

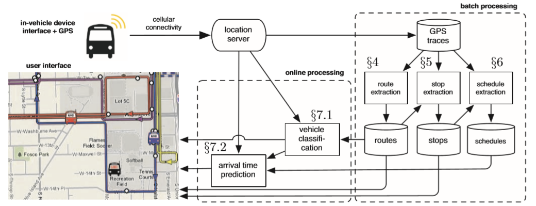
Unterschied zwischen Stapelverarbeitung und Stream -Verarbeitung
- 2697
- 516
- Hugo Poehn
Daten sind die neue Währung in der heutigen digitalen Wirtschaft. Viele Unternehmen nutzen Big Data und Cloud-Technologien, um die traditionelle IT-Infrastruktur zu verbessern und datengesteuerte Kultur und Entscheidungsfindung zu unterstützen, während die Rechenzentren modernisiert werden. Virtualisierung und Automatisierung sind jedoch nur Teil des Übergangs zu einer Cloud -Umgebung. Die Ansätze zur Erfüllung wachsender Geschäftsanforderungen müssen für das Unternehmen angepasst werden. Während Cloud Computing nichts weniger als eine revolutionäre Verschiebung in der Branche ist und Cloud -basierte Technologien der Schlüssel zur Gewährleistung einer ausgeklügelten Datenverwaltungsstruktur sind, besteht die Herausforderung darin, die Verarbeitung von Daten schneller zu verarbeiten - Stapelverarbeitung oder Stream -Verarbeitung. Jeder hat seine Vor- und Nachteile, aber alles hängt von Ihrem Geschäftsgebrauchsfall ab. Schauen wir uns die beiden Ansätze an und finden Sie die Unterschiede zwischen den beiden heraus.
Was ist die Stapelverarbeitung?
Die Stapelverarbeitung ist eine Methode zur Verarbeitung hoher Datenmengen in einer Gruppe oder Stapel innerhalb eines bestimmten Zeitintervalls. Die Systeme führen eine Reihe von Programmen aus, die eine Reihe von Datendateien als Eingabe aufnehmen, die Daten verarbeitet und eine Reihe von Datendateien als Ausgabe erzeugen. Ein gutes Beispiel für die Batch -Verarbeitung sind Gehalts- und Abrechnungssysteme, bei denen alle zugehörigen Daten gesammelt und gehalten werden, bis die Rechnung am Ende eines jeden Monats als Stapel bearbeitet wird. Es ist die Verarbeitung der Datenblöcke, die bereits über einen bestimmten Zeitraum gespeichert wurden. Es wird so genannt, weil die Daten in Stapeln als Datensätze gesammelt und als Einheit verarbeitet werden. Die Ausgabe ist eine weitere Charge, die bei Bedarf als Eingang wiederverwendet werden kann. Die Einfachheit und Raffinesse des Stapelsystems ermöglicht auch eine parallele Verarbeitung, e.G., Hadoop.
Was ist Stream -Verarbeitung?
Die Stream -Verarbeitung ist eine Methode, mit der der kontinuierliche Datenstrom abfragt und Bedingungen innerhalb eines begrenzten Zeitraums schnell erfasst. Mit anderen Worten, die Stream -Verarbeitung ist die Verarbeitung von Daten direkt, wie sie erzeugt oder empfangen werden. Stream -Verarbeitungssysteme ernähren sich häufig von Aktionen, die in Echtzeit wie Social -Media -Nachrichten, Webseiten, E -Commerce -Transaktionen, Sensorlesungen usw. auftreten. Diese Systeme sollten eine schnellere Verarbeitungsrate aufweisen als die Rate der eingehenden Daten. Die grundlegende Idee der Stream-Verarbeitung ist, dass die Systeme langlebig sein sollen und sich mit einem kontinuierlichen Datenstrom befassen sollen. Um Wert aus Big Data zu erhalten, müssen Daten so schnell wie sie eintreffen und gleichzeitig die Datenqualität beibehalten. Eine effektive Stream-Verarbeitung kann eine Vielzahl von realen Problemen lösen. Zum Beispiel kann Stream zur Erkennung von Betrug, Entscheidungsfindung, Musterlernen usw. verwendet werden.
Unterschied zwischen Stapelverarbeitung und Stream -Verarbeitung
Definition
- Die Batch -Verarbeitung ist eine Methode zur Verarbeitung hoher Datenmengen in einer Gruppe oder Stapel innerhalb einer bestimmten Zeitspanne. Es wird als Stapelverarbeitung bezeichnet, da die Daten in Stapeln als Datensätze gesammelt und als Einheit verarbeitet werden. Die Ausgabe ist eine weitere Charge, die bei Bedarf als Eingang wiederverwendet werden kann. Die Stream -Verarbeitung hingegen ist eine Methode zur direkten Verarbeitung von Daten, wie sie erzeugt oder empfangen werden. Es wird verwendet, um einen kontinuierlichen Datenstrom abzufragen und Bedingungen innerhalb eines begrenzten Zeitraums schnell zu erkennen.
Modell
- In der Stapelverarbeitung führt das System eine Reihe von Programmen aus, die eine Reihe von Datendateien als Eingabe aufnehmen, die Daten verarbeitet und eine Reihe von Datendateien als Ausgabe erzeugt. Die Eingabekomponente ist für das Sammeln von Daten aus mehreren Quellen, normalerweise Datenbanken, verantwortlich, und die Verarbeitungskomponente ist für die Durchführung von Berechnungen mit diesen Eingängen verantwortlich. Schließlich generiert die Ausgabekomponente Ergebnisse, die in die Datenbanken zurückgeschrieben werden. In der Stream -Verarbeitung führt das System die Verarbeitung nach den neuesten Daten aus, was bedeutet.
Beispiel
- Das beste Beispiel für Batch -Verarbeitungssysteme sind Gehalts- und Abrechnungssysteme, bei denen alle zugehörigen Daten gesammelt und gehalten werden, bis die Rechnung am Ende eines jeden Monats als Stapel bearbeitet wird. Viele verteilte Programmierplattformen wie MapReduce, Spark, Graphx und HTCondor sind Stapelverarbeitungssysteme. Die Stream -Verarbeitung kann als Online -Lösung für die Betrugserkennung verwendet werden und für Anwendungen verwendet werden, die kontinuierliche Ausgaben von eingehenden Daten wie Aktienmarkt, Social -Media -Nachrichten, E -Commerce -Transaktionen, Sensorwerte usw. benötigen. Big Data -Programmierungsplattformen wie Storm, Spark Streaming und S4 sind Stream -Verarbeitungssysteme.
Batch -Verarbeitung vs. Stream -Verarbeitung: Vergleichstabelle

Zusammenfassung der Batch -Verarbeitung vs. Stream -Verarbeitung
Während Stapelverarbeitungssysteme im Vergleich zu Stream -Verarbeitungssystemen deutlich weniger komplex und anspruchsvoller sind, wirken die Kosten für Stapelverarbeitungssysteme für einige Unternehmen und Organisationen, die zunächst keine teure Hardware haben, weniger machbar. Stream-Verarbeitungssysteme können jedoch in Anwendungen verwendet werden, die kontinuierliche Ausgaben aus eingehenden Daten in Echtzeit wie Social-Media-Anwendungen, Aktienmarkt usw. benötigen, usw. Während die Stream-Verarbeitung am besten für Unternehmensanwendungsfälle geeignet ist, in denen Zeit eine Einschränkung ist, funktioniert die Stapelverarbeitung gut, wenn alle Zusammenhänge vorgeladen wurden. Es kommt also alles auf Ihren Geschäftsgebrauchsfall an.
- « Unterschied zwischen dem übermäßigen und unbeaufsichtigten Data Mining
- Unterschied zwischen Backplane und Motherboard »