

Unterschied zwischen dem übermäßigen und unbeaufsichtigten Data Mining

- 3861
- 641
- Cem Schlitzer
Data Mining nutzt eine Vielzahl von Rechenmethoden und Algorithmen, um an der Wissensextraktion zu arbeiten. Die Klassifizierung ist möglicherweise die grundlegendste Form der Datenanalyse. Eine häufige Aufgabe im Data Mining ist die Untersuchung von Daten, bei denen die Klassifizierung unbekannt ist oder in Zukunft auftreten wird, mit dem Ziel, vorherzusagen, wie diese Klassifizierung ist oder sein wird. In ähnlicher Weise werden Daten, bei denen die Klassifizierung bekannt ist. Davon abgesehen werden die Techniken des Data Mining in zwei Hauptformen geliefert: beaufsichtigt und unbeaufsichtigt. Überwacht ist eine prädiktive Technik, während unbeaufsichtigt eine beschreibende Technik ist. Obwohl beide Algorithmen häufig verwendet werden, um unterschiedliche Data -Mining -Aufgaben zu erledigen, ist es wichtig, den Unterschied zwischen den beiden zu verstehen.
Was wird überwachtes Data Mining?
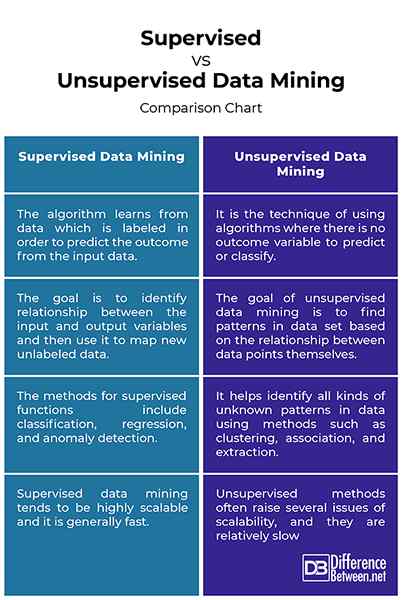
Beaufsichtigtes Data Mining bezieht sich, wie der Name schon sagt, auf Lernalgorithmen, die in der Klassifizierung und Vorhersage verwendet werden. Der beaufsichtigte Algorithmus lernt aus den bezeichneten Trainingsdaten und die Aufgabe wird vom Wissensingenieur und des Systemdesigners gesteuert. Mit überwachten Daten müssen wir bekannt sind, dass Eingänge bekannte Ausgänge entsprechen, wie von Domänenexperten bestimmt. Die Data Mining -Aufgabe wird häufig als überwachtes Lernen bezeichnet, da die Klassen vor der Untersuchung der Daten ermittelt werden. Diese Technik verwendet eine objektive Funktion (die abhängige Variable) und eine Reihe von Datenelementen, die unabhängige Variablen sind. Übersichtliche Technik versucht, Beziehungen zwischen abhängigen und unabhängigen Variablen zu identifizieren, den Korrelationsgrad für jeden Satz von Variablen zu identifizieren und ein Modell zu erstellen, das das Netz der Abhängigkeiten zeigt. Das Modell wird dann auf die Daten angewendet, für die der Zielwert unbekannt ist.

Was ist unbeaufsichtigtes Data Mining?
Im Gegensatz zur beaufsichtigten Technik hat das unbeaufsichtigte Data Mining keine vorbestimmte objektive Funktion und prognostiziert auch keinen Zielwert. Unbewegte Techniken sind solche, bei denen keine Ergebnisvariable vorhersagen oder klassifiziert werden kann. Daher gibt es kein Lernen aus Fällen, in denen eine solche Ergebnisvariable bekannt ist. Der Algorithmus verlangt vom Benutzer, die Anzahl der Intervalle und/oder wie viele Datenpunkte in einem bestimmten Intervall enthalten sein sollten. Es hilft Ihnen, alle möglichen unbekannten Muster in Daten zu identifizieren. Das unbeaufsichtigte Modell wird auch als deskriptives Modell bezeichnet, da es nach unbekannten Muster in einem Datensatz ohne vorgegebene Etiketten und ohne oder minimale menschliche Überwachung sucht. Unbewegte Lernmethoden umfassen Clustering-, Assoziations- und Extraktionsmethoden. Diese Art von Lerntechnik wird verwendet, wenn ein bestimmtes Ziel nicht verfügbar ist oder wenn der Benutzer versucht, versteckte Beziehungen in Daten zu finden.
Unterschied zwischen dem übermäßigen und unbeaufsichtigten Data Mining
Daten
- Überwachendes Lernen ist die Data Mining -Aufgabe der Verwendung von Algorithmen zur Entwicklung eines Modells für bekannte Eingabe- und Ausgabedaten. Dies bedeutet, dass der Algorithmus aus Daten lernt, die gekennzeichnet sind, um das Ergebnis aus den Eingabedaten vorherzusagen. Die beaufsichtigte Technik lernt einfach aus dem Trainingsdatensatz. Unüberständiger Lernen hingegen ist die Technik, Algorithmen zu verwenden, bei denen keine Ergebnisvariable für die Vorhersage oder Klassifizierung besteht, was bedeutet, dass es kein Lernen aus Fällen gibt, in denen eine solche Ergebnisvariable bekannt ist.
Ziel
- Übersichtliche Technik versucht, lässige Beziehungen zwischen abhängigen und unabhängigen Variablen zu identifizieren, den Korrelationsgrad für jeden Satz von Variablen zu isolieren und ein Modell zu entwickeln, das das Netz der Abhängigkeiten zeigt. Das Modell wird dann auf Daten angewendet, für die der Zielwert unbekannt ist. Unüberwachtes Lernen versucht, unbekannte Muster in einem Datensatz ohne vorbestimmte Beschriftungen und ohne oder minimale menschliche Aufsicht zu identifizieren. Das Ziel von unbeaufsichtigten Data Mining -Techniken ist es, Muster im Datensatz basierend auf der Beziehung zwischen Datenpunkten selbst zu finden.
Methode
- Beaufsichtige Modelle sind diejenigen, die in Klassifizierung und Vorhersage verwendet werden, daher als Vorhersagemodelle bezeichnet, weil sie aus den Trainingsdaten lernen, nämlich die Daten, aus denen die Klassifizierung oder der Vorhersagealgorithmus lernt. Sobald der Algorithmus aus den Trainingsdaten gelernt hat, wird er dann auf eine andere Stichprobe von Daten angewendet, in denen das Ergebnis bekannt ist. Die Methoden umfassen die folgenden beaufsichtigten Funktionen: Klassifizierung, Regression und Anomalieerkennung. Unüberwachte Data Mining hilft Ihnen, alle Arten von unbekannten Muster in Daten mithilfe von Methoden wie Clustering, Assoziation und Extraktion zu identifizieren.
Skalierbarkeit
- Skalierbarkeit ist eines der Hauptprobleme beim Mining großer Datensätze und es ist nicht praktisch, den gesamten Datensatz mehr als einmal zu analysieren. Der überwachte Data Mining ist tendenziell sehr skalierbar, was bedeutet, dass es in Zeitrahmen enorme Datenmengen umgehen kann. Unbewegte Lernmethoden andererseits aufwerfen häufig mehrere Probleme, wenn es um Skalierbarkeit geht, wenn eine Art parallele Bewertung nicht verwendet wird, und im Gegensatz zum überwachten Lernen ist es relativ langsam, kann jedoch in Richtung mehrerer Sätze von Lösungszuständen konvergieren.
Beaufsichtigt vs. Unüberwachter Data Mining: Vergleichstabelle
Zusammenfassung
Kurz gesagt, beaufsichtigte Data Mining ist eine Vorhersagetechnik, während unbeaufsichtigter Data Mining eine beschreibende Technik ist. Beaufsichtige Techniken werden verwendet, wenn ein bestimmtes Ziel verfügbar ist und der Benutzer versucht, festzustellen, wie die Änderungen im Datenzustand das Ergebnis beeinflussen. Unbewegter Data Mining dagegen startet mit einem sauberen Schiefer, dh es gibt keine vordefinierte objektive Funktion und der Benutzer versucht, unbekannte Muster oder verborgene Beziehungen in den Daten zu finden. Das Ziel des unbeaufsichtigten Data Mining besteht darin, Muster im Datensatz basierend auf der Beziehung zwischen Datenpunkten selbst zu finden.
- « Unterschied zwischen Data Mining und Datenprofiling
- Unterschied zwischen Stapelverarbeitung und Stream -Verarbeitung »