

Unterschied zwischen dynamischem und statischem Hashing
- 3459
- 1029
- Kurt Reinelt
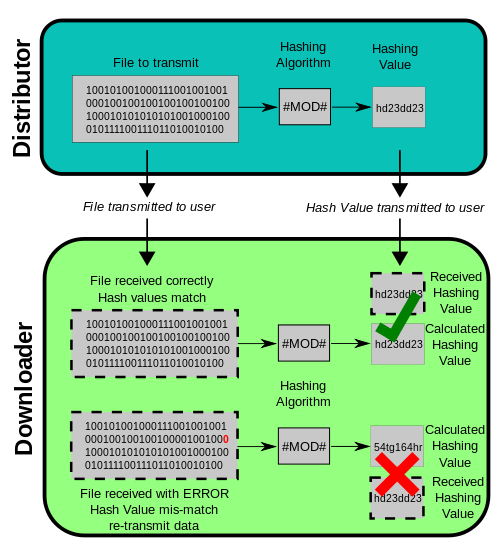
In der Datenstruktur ist Hashing eine Technik, um eine große Anzahl von Datenelementen auf kleinere Tabellen zuzuordnen, unter Verwendung einer speziellen Funktion, die als Hash -Funktion für einen schnelleren Zugriff bezeichnet wird. Manchmal ist die Datenstruktur so groß, dass es fast unmöglich wird, alle Indexwerte über alle Ebenen zu durchsuchen, um auf den endgültigen Datenblock zuzugreifen. Hier kommt Hashing direkt hinein. Was es tut, berechnet den Speicherort eines Datendatensatzes auf der Festplatte direkt, ohne die Indexstruktur zu verwenden. Die Adresse jedes Datensatzes wird unter Verwendung eines Hashing -Algorithmus ermittelt, der einen Primärschlüsselwert in eine Datensatzadresse umwandelt. Es gibt also zwei Kategorien von Indexierung unter Verwendung von Hash -Funktionen - dynamisches Hashing und statisches Hashing.
Was ist statisches Hashing?
Statisches Hashing ist eine Methode zum Hashing, bei der eine feste Anzahl von Eimer einer Datei zugewiesen wird, um die Datensätze zu speichern. Die Anzahl der Eimer ist vorab zusammenalzikt. Wenn ein Suchschlüsselwert bereitgestellt wird. Die Seite einer Datei kann als Sammlung von Eimer mit einer Primärseite und zusätzlichen Überlaufseiten angesehen werden. Mit statischer Hashing ist der Standortmechanismus die Hash -Funktion und es sind keine Datenstrukturen beteiligt. Hier werden die Indexeinträge so randomisiert, dass die Anzahl der Indexeinträge in jedem Eimer ungefähr gleich ist. Es gibt jedoch auch bestimmte Nachteile in diesem Schema. Wenn die anfängliche Anzahl der Eimer zu klein ist und die Datei wächst, verschlechtert sich die Leistung aufgrund von Bucket -Überläufen. Andererseits wird ein Großraum für das erwartete Wachstum viel Platz bereitgestellt, wenn es zu groß ist, und eine erhebliche Menge an Platz verschwendet.
Was ist dynamisches Hashing?
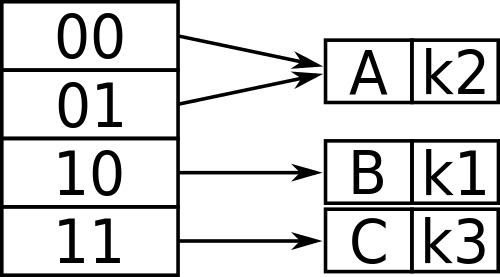
Dynamisches Hashing hingegen ist eine Technik, mit der die Einschränkungen des statischen Hashings wie den Bucket -Überlauf überwunden werden. Im Gegensatz zu statischer Hashing können die Anzahl der Eimer dynamisch variieren, um das Wachstum oder die Schrumpfung von Datenbankdateien zu berücksichtigen. Es ermöglicht die Änderung der Hash -Funktion bei Bedarf, die für Datenbanken, die wachsen und in der Größe schrumpfen, gut geeignet ist. Wenn Zeilen hinzugefügt und gelöscht werden, ändert es die Anzahl der Eimer entsprechend, um den Überlauf der Eimer zu minimieren. Es einbettet die Handhabung von Überlaufaufzeichnungen dynamisch in den primären Adressraum ein, um die Verwaltung von Überlaufklappen zu vermeiden. Die beiden häufig verwendeten Formen von dynamischem Hashing sind lineares Hashing und erweiterbares Hashing. Extendible Hashing ist eine beliebte Technik, die den Bucket Overflow durch Aufspalten eines Eimers in zwei Teile umgeht, wobei die Aufzeichnungen zwischen alten und neuen Eimern verteilt werden. Lineares Hashing ist eine weitere beliebte Form des dynamischen Hashings, mit der eine Hash -Datei dynamisch wachsen oder schrumpfen kann.
Unterschied zwischen dynamischem und statischem Hashing
Technik
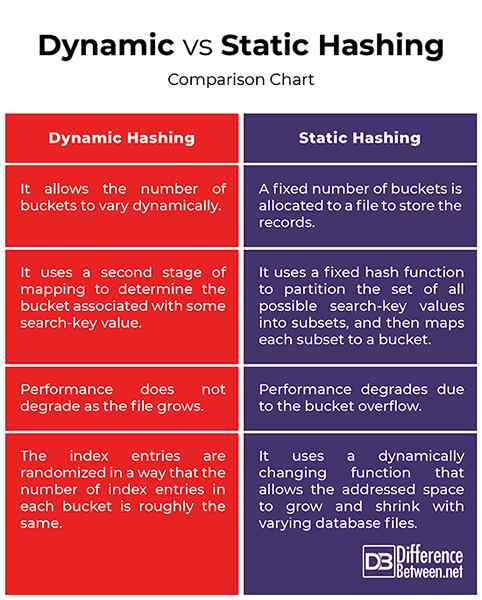
- Static Hashing ist eine Methode zum Hashing, bei der eine feste Anzahl von Eimer einer Datei zugewiesen wird, um die Datensätze zu speichern, was bedeutet, dass sie eine Hash -Funktion verwendet. Hier werden die Indexeinträge so randomisiert, dass die Anzahl der Indexeinträge in jedem Eimer ungefähr gleich ist. Dynamisches Hashing ermöglicht es andererseits, dass die Anzahl der Eimer dynamisch variiert, um das Wachstum oder die Schrumpfung von Datenbankdateien aufzunehmen.
Leistung
- Wenn die anfängliche Anzahl der Eimer zu klein ist und die Datei wächst, verschlechtert sich die Leistung aufgrund von Bucket -Überläufen. Andererseits wird ein Großraum für das erwartete Wachstum viel Platz bereitgestellt, wenn es zu groß ist, und eine erhebliche Menge an Platz verschwendet. Dynamisches Hashing ermöglicht es dynamisch, dass die Hash -Funktion dynamisch geändert wird, was für Datenbanken gut ist, die wachsen und schrumpfen. Wenn Zeilen hinzugefügt und gelöscht werden, ändert es die Anzahl der Eimer entsprechend, um den Überlauf der Eimer zu minimieren.
Implementierung
- Static Hashing verwendet eine feste Hash-Funktion, um die Menge aller möglichen Suchschlüsselwerte in Teilmengen zu partitionieren und dann jede Teilmenge an einen Eimer zuzuordnen. Dynamisches Hashing hingegen verwendet eine zweite Mapping-Stufe, um den Eimer zu bestimmen, der einem Suchschlüsselwert zugeordnet ist. Erweiterbares und lineares Hashing macht diese Zuordnung sehr unterschiedlich.
Dynamisch vs. Statisches Hashing: Vergleichstabelle
Zusammenfassung
Die Anzahl der Eimer ist in statischer Hashing festgelegt und Aufzeichnungen mit unterschiedlichen Suchschlüsselwerten weisen auf denselben Eimer hin. In diesem Fall kann eine Kollision auftreten. Wenn Sie einen bestimmten Datensatz in einem Eimer mit mehreren Schlüssel suchen müssen, müssen Sie den gesamten Bucket nacheinander durchsuchen. Manchmal hat ein Eimer mehr Datensätze, als er enthalten kann. In diesem Fall müssen also einige Überlaufhandhabungstechniken aufgerufen werden. In diesem Fall wird dynamisches Hashing verwendet, das eine dynamisch ändernde Funktion verwendet, die es ermöglicht, die Anzahl der zugewiesenen Eimer zu wachsen und zu schrumpfen, wenn Zeilen hinzugefügt und gelöscht werden. Es behandelt explizit den Überlauf der Eimer, indem die Überlaufaufzeichnungen dynamisch in seine primäre Adresse eingebettet werden.