

Unterschied zwischen Dispersion und Schiefe
- 3429
- 402
- Leonhard Lesch
Der Grad der Variationen wird häufig in Bezug auf numerische Daten zum alleinigen Zweck des Vergleichs in der statistischen Theorie und Analyse ausgedrückt. Normalerweise berechnen wir eine einzelne Abbildung, um den gesamten Datensatz darzustellen, der als „Durchschnitt“ bezeichnet wird. Es gibt jedoch keine besondere Möglichkeit, die Zusammensetzung von Serien zu bestimmen. Aus diesem Grund sind zusätzliche Maßnahmen erforderlich, um uns darüber aufzuklären, wie die Gegenstände voneinander oder um den Durchschnitt variieren. Um die viel detaillierten Konzepte der quantitativen Analyse in Statistiken zu verstehen, verwenden wir Maßnahmen für Dispersion und Schiefe. Die Dispersion ist ein Maß für die Verteilung der Verteilung rund um den zentralen Ort, während die Schiefe ein Maß für die Asymmetrie in einer statistischen Verteilung ist.
Was ist Dispersion?
In Statistiken ist Dispersion ein Maß dafür, wie verteilt die Daten bedeutet, wie sich die Werte innerhalb eines Datensatzes in der Größe voneinander unterscheiden. Es ist der Bereich, auf den sich eine statistische Verteilung um einen zentralen Punkt ausbreitet. Es bestimmt hauptsächlich die Variabilität der Elemente eines Datensatzes um seinen zentralen Punkt. Einfach ausgedrückt, misst es den Grad der Variabilität um den Mittelwert um den Mittelwert. Die Dispersionsmaßnahmen sind wichtig, um die Ausbreitung von Daten um ein Maß für den Standort zu bestimmen. Beispielsweise ist die Varianz ein Standardmaß für die Dispersion, das feststellt, wie die Daten über den Mittelwert verteilt sind. Andere Dispersionsmaßnahmen sind Bereiche und durchschnittliche Abweichungen.
Was ist Schiefe?
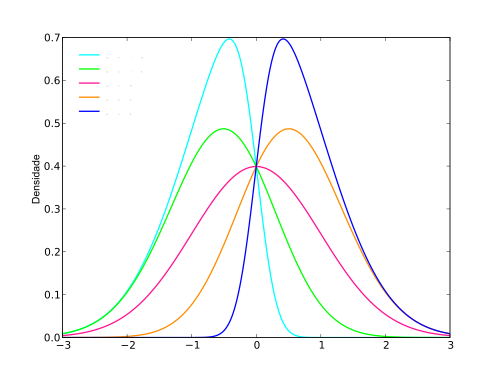
Schiefe ist ein Maß für die Verteilung der Verteilung über einen bestimmten Punkt. Eine Verteilung kann leicht asymmetrisch, stark asymmetrisch oder symmetrisch sein. Das Maß für die Asymmetrie einer Verteilung wird unter Verwendung von Schiefe berechnet. Im Falle einer positiven Schiefe soll die Verteilung rechtsschwankend sein, und wenn die Schiefe negativ ist. Wenn die Schiefe Null ist, ist die Verteilung symmetrisch. Die Schiefe wird anhand von Mittelwert, Median und Modus gemessen. Der Wert der Schiefe kann positiv, negativ oder undefiniert sein, je nachdem, ob die Datenpunkte nach links verzerrt oder nach rechts verzerrt sind.
Unterschied zwischen Dispersion und Schiefe
-
Definition von Dispersion vs. Schiefe
In statistischer Begriffe und Wahrscheinlichkeitstheorie ist Dispersion die Größe des Wertebereichs für eine Zufallsvariable oder ihre Wahrscheinlichkeitsverteilung. Es beschreibt einen Bereich, auf den eine Verteilung gedehnt oder verbreitet ist. Einfach ausgedrückt, es ist eine Maßnahme, die Variabilität der Elemente zu untersuchen. Die Schiefe hingegen ist ein Maß für die Asymmetrie in einer statistischen Verteilung einer zufälligen Variablen über ihren Mittelwert. Der Wert der Schiefe kann sowohl positiv als auch negativ oder manchmal undefiniert sein. Einfach ausgedrückt, asymmetrische Verteilungen sollen verzerrt sein
-
Dispersionsmaßnahmen vs. Schiefe
Die Messungen der Dispersion haben das Ausmaß, in dem die Variationen von ihrem zentralen Wert ausgeschlossen sind. Genauer gesagt misst es den Variabilitätsgrad des Wertes einer Variablen um den Mittelwert. Die Dispersion gibt die Verbreitung der Daten an. Die Messungen der Schiefe bedeuten, wie asymmetrisch die Verteilung ist, und bestimmt, ob Datenpunkte nach rechts oder nach links verzerrt sind. Wenn die Verteilung nach links verzerrt ist, ist der Wert negativ und der Wert positiv, wenn die Verteilung nach rechts verzerrt ist.
-
Berechnung der Dispersion vs. Schiefe
Die Dispersion wird auf der Grundlage eines bestimmten Durchschnitts berechnet. Es handelt sich um eine statistische Berechnung, die den Variationsgrad misst, und es gibt viele verschiedene Möglichkeiten zur Berechnung der Dispersion, aber die beiden der häufigsten sind Bereiche und durchschnittliche Abweichungen. Bereich ist die Differenz zwischen den größten und den kleinsten Werten in einem Datensatz, während die durchschnittliche Abweichung der Durchschnitt der absoluten Werte der Abweichungen der Funktionswerte von einem zentralen Punkt ist. Die Schiefe hingegen wird auf der Grundlage von Mittelwert, Median und Modus berechnet. Wenn der Mittelwert größer als der Modus ist, haben Sie einen positiven Versatz und falls der Mittelwert geringer ist als der Modus, haben Sie einen negativen Versatz. Zusätzlich hat die Verteilung bei einer symmetrischen Verteilung einen Nullschub.
-
Dispersionsanwendungen vs. Schiefe
Dispersion wird hauptsächlich verwendet, um die Beziehung zwischen einem Datensatz zu beschreiben und den Grad der Variation der Datenwerte aus ihrem Durchschnittswert zu bestimmen. Statistische Dispersion kann für andere statistische Methoden wie Regressionsanalyse verwendet werden, bei der ein Prozess verwendet wird, um die Beziehung zwischen Variablen zu verstehen. Es kann auch verwendet werden, um die Zuverlässigkeit des Durchschnitts zu testen. Auf der anderen Seite befasst sich die Art der Verteilung in einer Reihe von Daten mit der Art der Verteilung. Es ist äußerst hilfreich, wenn es um die wirtschaftliche Analyse im Finanzsektor geht, bei der eine Menge Daten wie Vermögenswerte, Aktienkurse usw. beinhalten, usw.
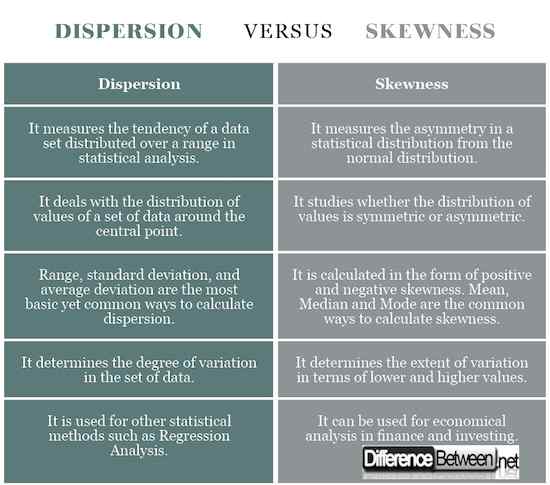
Dispersion vs. Schiefe: Vergleichstabelle
Zusammenfassung der Dispersion vs. Schiefe
Beide sind die häufigsten Begriffe, die in der statistischen Analyse und der Wahrscheinlichkeitstheorie verwendet werden, um einen Datensatz zu charakterisieren, der eine riesige massierte numerische Daten umfasst. Dispersion ist eine Maßnahme, um die Variabilität der Daten zu berechnen oder die Datenschwankungen untereinander oder um den Durchschnitt zu untersuchen. Es befasst sich hauptsächlich mit der Verteilung der Datenwerte in einem Satz um seinen zentralen Punkt. Es kann auf verschiedene Arten gemessen werden, von welchem Bereich und durch die durchschnittliche Abweichung am häufigsten sind. Die Schiefe wird verwendet, um die Asymmetrie aus der Normalverteilung in einem Datensatz zu messen, was bedeutet.
- « Unterschied zwischen realem Lohn und nominalem Lohn
- Unterschied zwischen absolutem und relativem Weg »