

Unterschied zwischen ORC und Parkett
- 2745
- 367
- Caitlin Rodehau
Sowohl ORC als auch Parquet sind beliebte Open-Source-Columnar-Dateispeicherformate im Hadoop-Ökosystem und sind in Bezug auf Effizienz und Geschwindigkeit ziemlich ähnlich, und vor allem sind sie so konzipiert, dass sie die Workloads von Big Data Analytics beschleunigen. Die Arbeit mit ORC-Dateien ist genauso einfach wie die Arbeit mit Parquetdateien, da sie effiziente Lesen- und Schreibfunktionen über ihre zeilenbasierten Gegenstücke bieten. Beide haben einen angemessenen Anteil an Vor- und Nachteilen, und es ist schwer herauszufinden, welches besser ist als der andere. Schauen wir uns jeden von ihnen besser an. Wir beginnen zuerst mit Orc und wechseln dann zum Parquet.
Ork
ORC, kurz für optimierte Zeilenspalten, ist ein kostenloses und Open-Source-Säulenspeicherformat für Hadoop-Workloads. Wie der Name schon sagt, ist ORC ein selbstbeschreibendes, optimiertes Dateiformat, das Daten in Spalten speichert, mit denen Benutzer nur die benötigten Teile lesen und dekomprimieren können. Es ist ein Nachfolger des Formats "Traditional Record Columnar File) (RCFILE). Der Zugriff auf Daten dauert deutlich weniger Zeit und reduziert auch die Größe der Daten auf 75 Prozent. ORC bietet eine effizientere und bessere Möglichkeit, Daten zu speichern, die über SQL-on-Hadoop-Lösungen wie Hive mit Tez zugegriffen werden können. ORC bietet viele Vorteile gegenüber anderen Hive -Dateiformaten, wie z.
Parkett
Parquet ist ein weiteres Open-Source-Dateiformat mit Spalten-orientiert. Parquet ist bei den Big -Data -Praktikern sehr beliebt, da es eine Vielzahl von Speicheroptimierungen bietet, insbesondere bei Workloads an der Analytics. Wie Orc bietet Parquet Columnar -Kompressionen, in denen Sie viel Speicherplatz ersparen können, während Sie einzelne Spalten lesen können, anstatt vollständige Dateien zu lesen. Es bietet erhebliche Vorteile in Bezug auf die Leistungs- und Speicheranforderungen in Bezug auf herkömmliche Speicherlösungen. Es ist effizienter darin, Daten zu Daten zu führen, und es ist sehr flexibel, wenn es darum geht, eine komplexe verschachtelte Datenstruktur zu unterstützen. In der Tat ist es besonders konzipiert, verschachtelte Datenstrukturen im Auge zu behalten. Parquet ist auch ein besseres Dateiformat bei der Reduzierung der Speicherkosten und zur Beschleunigung des Leseschritts, wenn es um große Datensätze geht. Parquet funktioniert sehr gut mit Apache Spark. Tatsächlich ist es das Standarddateiformat zum Schreiben und Lesen von Daten in Spark.
Unterschied zwischen ORC und Parkett
Herkunft
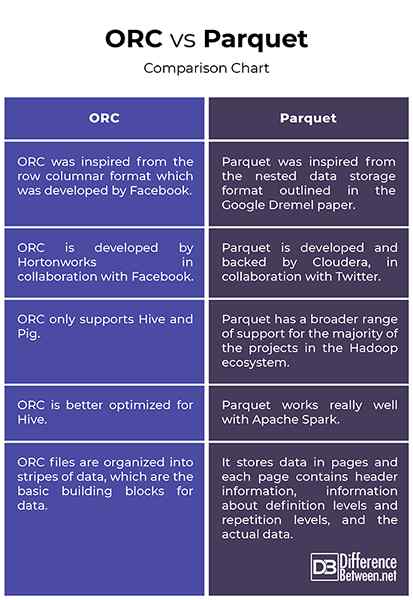
- ORC wurde aus dem Zeilen -Columnar -Format inspiriert, das von Facebook entwickelt wurde, um Columnar Reads, Pushictive Pushdown und Lazy Reads zu unterstützen. Es ist ein Nachfolger des RCFILE -Formats (Traditional Record Columnar File) und bietet eine effizientere Möglichkeit, relationale Daten zu speichern als das RCFILE, wodurch die Größe der Daten um bis zu 75 Prozent verringert wird. Das Parquet hingegen wurde von dem im Google Dremel -Papier beschriebenen verschachtelten Datenspeicherformat inspiriert und von Cloudera in Zusammenarbeit mit Twitter entwickelt. Parquet ist jetzt ein Apache -Inkubatorprojekt.
Unterstützung
- Sowohl ORC als auch Parquet sind beliebte Spalten-orientierte Big-Datendatei-Formate, die fast ein ähnliches Design teilen, da beide Daten in Spalten teilen. Während das Parquet für die Mehrheit der Projekte im Hadoop -Ökosystem eine viel breitere Unterstützung für die meisten Projekte hat, unterstützt Orc nur Bienenstock und Schwein. Ein wesentlicher Unterschied zwischen beiden besteht darin, dass ORC für Bienenstock besser optimiert ist, während Parquet sehr gut mit Apache Spark funktioniert. Tatsächlich ist Parquet das Standarddateiformat zum Schreiben und Lesen von Daten in Apache Spark.
Indizierung
- Die Arbeit mit ORC -Dateien ist genauso einfach wie die Arbeit mit Parquetendateien. Beide eignen sich hervorragend für leseblastige Workloads. ORC -Dateien werden jedoch in Datenstreifen organisiert, die die grundlegenden Bausteine für Daten sind und voneinander unabhängig sind. Jeder Stripe verfügt über Index-, Zeilendaten und Fußzeile. In der Fußzeile sind die Schlüsselstatistiken für jede Spalte innerhalb eines Streifens wie Graf, Min, Max und Summe zwischengespeichert. Parquet hingegen speichert Daten in Seiten und jede Seite enthält Headerinformationen, Informationen zu Definitionsniveaus und Wiederholungsstufen und die tatsächlichen Daten.
Orc vs. Parquet: Vergleichstabelle
Zusammenfassung
Sowohl ORC als auch Parquet sind zwei der beliebtesten Open-Source-Spalten-Speicherformate im Hadoop-Ökosystem, die so konzipiert sind. Parquet wurde von Cloudera und Twitter zusammen entwickelt, um die Probleme mit der Speicherung großer Datensätze mit hohen Spalten zu lösen. ORC ist der Nachfolger der traditionellen RCFile -Spezifikation und die im ORC -Dateiformat gespeicherten Daten sind in Streifen organisiert, die für HDFS -Lesevorgänge hoch optimiert sind. Parquet hingegen ist eine bessere Wahl in Bezug auf die Anpassungsfähigkeit, wenn Sie mehrere Tools im Hadoop -Ökosystem verwenden. Parquet ist besser für die Verwendung mit Apache Spark optimiert, während ORC für Hive optimiert ist. Aber zum größten Teil sind beide ziemlich ähnlich, ohne signifikante Unterschiede zwischen den beiden.
- « Unterschied zwischen Quarantäne und Selbstisolation
- Unterschied zwischen Crowdsourcing und Crowdfunding »