

Unterschied zwischen HBase und Bienenstock
- 3303
- 468
- Prof. Dr. Charleen Lammert
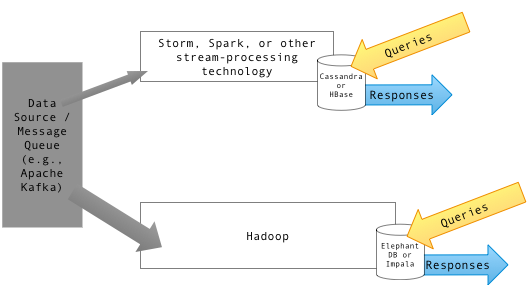
HBase und Hive sind beide Hadoop -basierte Data Warehouse -Strukturen auf Hadoop -Basis, die sich erheblich in Bezug auf die Speicherung und Abfragedaten unterscheiden. Die Verwaltung und Verarbeitung großer Mengen webbasierter Daten werden durch herkömmliche Datenbankmanagement-Tools immer schwieriger. Hier kommt HBase zum Bild. HBase ist eine bevorzugte Wahl, um große Datenmengen zu bewältigen. Wenn Sie beispielsweise einen riesigen Speicher von E -Mails durchführen müssen, um eine für die Prüfung oder für einen anderen Zweck herauszuholen, ist dies ein perfekter Anwendungsfall für HBASE. Hive hingegen ähnelt eher ein traditionelles Data Warehouse -Berichtssystem, das auf Hadoop läuft. Hive bietet eine SQL-ähnliche Abfragesprache, mit der Sie die in Hadoop gespeicherten halbstrukturierten Daten abfragen können. Dies erfordert unnötige Anstrengung, MapReduce -Code schreiben zu müssen. Obwohl sowohl HBase als auch Hive als Datenspeicher verwendet werden, um unstrukturierte Daten zu speichern, sind sie unterschiedlich.
Was ist HBase?
HBase ist ein Open-Source-Datenbankverwaltungssystem, das von der Big Table-Architektur der Google inspiriert und in Java geschrieben wurde. HBase ist grundsätzlich eine spaltenorientierte, verteilte NoSQL-Datenbank, die über dem Hadoop-Distributed Dateisystem (HDFS) ausgeführt wird. Es wurde von vielen Ingenieuren im Rahmen der Apache Software Foundation entworfen und entwickelt. Es befindet sich auf Apache Hadoop und wird von einer verteilten Dateistruktur für Fehlertoleranze betrieben, die als HDFS bezeichnet wird. Es bietet eine Möglichkeit, spärliche Datensätze zu speichern, die in Big -Data -Anwendungsfällen üblich sind. Es ermöglicht schnelle Lesevorgänge von Zufallszugriffsdaten aus großen Datenmengen basierend auf den Schlüsselwerten. Es ist jedoch nicht so konzipiert, dass die Daten Aggregationen durchführen.
Was ist Bienenstock?
Hive ist nicht gerade eine Datenbank, sondern ein Data Warehousing -Paket, das auf Hadoop erstellt wurde. Hive ist eine andere Technologie als HBase; Es strukturiert die Daten in einer Reihe von Tabellen, die bei der Verwendung einer Abfragesprache namens Hive Query Language (HQL) verbunden, aggregiert und abgefragt werden können. Sie können die in Hadoop gespeicherten semi-strukturierten Daten abfragen, die schließlich in einen MapReduce-Job verwandelt, der entweder lokal oder auf einem verteilten MapReduce-Cluster ausgeführt wird. Hive ist im Grunde ein Data Warehouse-System für Hadoop, das eine einfache Datenübersicht, Ad-hoc-Abfragen und die Analyse großer Datensätze erleichtert, die in Hadoop-kompatiblen Dateisystemen gespeichert sind. Daten können aus Hive und HBase und umgekehrt gelesen und geschrieben werden. Es kann jedoch nicht zur Echtzeitverarbeitung von Daten verwendet werden.
Unterschied zwischen HBase und Bienenstock
Technologie
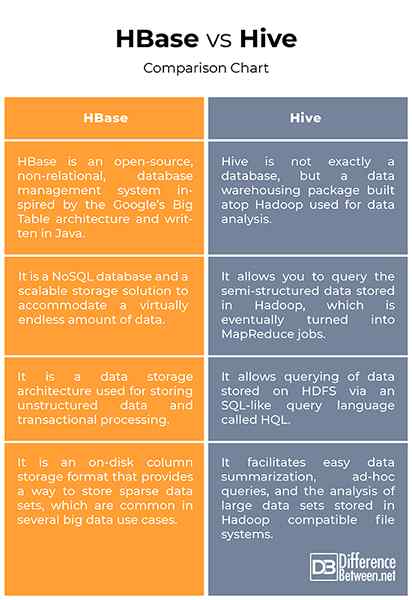
- Obwohl HBase und Hive beide Hadoop -basierte Data Warehouse -Strukturen basieren, die zum Speichern und Verarbeiten großer Datenmengen verwendet werden, unterscheiden sie sich erheblich, wie sie Daten speichern und abfragen. HBase ist im Grunde eine spaltenorientierte, verteilte NoSQL-Datenbank, die über dem Hadoop Distributed Dateisystem (HDFS) ausgeführt wird und eine fehlertolerante Möglichkeit bietet, spärliche Datensätze zu speichern, die in Big-Data-Anwendungsfällen üblich sind. Hive hingegen ist nicht gerade eine Datenbank, sondern ein Data Warehousing -Paket, das auf Hadoop erstellt wurde. Hive ähnelt eher ein traditionelles Data Warehousing -Berichtssystem.
Die Architektur
- HBase ist eine NoSQL-Datenbank und eine Open-Source-Implementierung der großen Tabellenarchitektur der Google, die auf Apache Hadoop sitzt und von einer fehlertoleranten verteilten Dateistruktur mit HDFS angetrieben wird. Es handelt sich um eine skalierbare Speicherlösung, um eine praktisch endlose Datenmenge aufzunehmen. Es handelt sich um eine Datenspeicherarchitektur, die zum Speichern unstrukturierter Daten verwendet wird. Hive hingegen ist eine SQL-Engine, die auf HDFs aufgebaut ist, und nutzt MapReduce intern, sodass die auf HDFs gespeicherten Daten über eine SQL-ähnliche Abfragesprache namens HQL (Hive Query Language) über eine SQL-ähnliche Abfragestraße ermöglicht werden können (Hive-Query-Sprache).
Verwenden
- HBASE wird verwendet, um ein kostengünstiges, flexibel und einfach zu verwaltender Kachelschichtdienste zu erstellen - Hadoop -basierte geografische Informationssystem (HBGIS) -, um eine massive Datenspeicherung zu erhalten. Es handelt sich um ein Speicherformat für das Spalten von On-Disk-Spalten, das eine Möglichkeit bietet, spärliche Datensätze zu speichern. Es ermöglicht schnelle Lesevorgänge von Zufallszugriffsdaten aus großen Datenmengen basierend auf den Schlüsselwerten. Hive hingegen ist ein Standard für SQL-Abfragen über Petabyte von Daten in Hadoop und bietet eine SQL-ähnliche Abfragesprache namens HQL zum Abfragen von Daten, die in einem Hadoop-Cluster gespeichert sind.
Hbase vs. Hive: Vergleichstabelle
Zusammenfassung
Obwohl HBase und Hive beide Hadoop -basierte Data Warehouse -Strukturen basieren, die zum Speichern und Verarbeiten großer Datenmengen verwendet werden, unterscheiden sie sich erheblich, wie sie Daten speichern und abfragen. HBASE ist ein spaltenorientiertes Datenbankverwaltungssystem, das für eine massive Datenspeicherung verwendet wird, und bietet eine Möglichkeit, spärliche Datensätze zu speichern, die in mehreren Big-Data-Anwendungsfällen üblich sind. Hive ist andererseits eher ein herkömmliches Data Warehouse -Berichtssystem, das auf Hadoop erstellt wurde, um die Verarbeitung durch Schedules -Jobs auszuführen, und dann die Ergebnisse in eine zusammenfassende Tabelle zu laden, die von Client -Anwendungen weiter abgefragt werden kann.
- « Unterschied zwischen Influencer -Marketing und Content -Marketing
- Unterschied zwischen Hadoop und MongoDB »