

Unterschied zwischen Hadoop und MongoDB
- 3419
- 96
- Justus Dengler
Wir hören den Begriff Big Data schon seit einiger Zeit, aber was genau ist diese Big Data? Die Datenmenge, die im Internet der Dinge erstellt wurden. Die Verarbeitung dieser massiven Datenmengen, die nicht für herkömmliche Methoden geeignet sind, wird als Big Data bezeichnet. Diese Art von Daten stellt die herkömmlichen RDBMS. Die Verarbeitungsleistung, die zum Speichern und Verarbeiten so viel Daten auf zeitnahe und kostengünstige Weise erforderlich ist, ist massiv. Um dieses Problem anzugehen, sind neue und verbesserte Big -Data -Lösungen erforderlich. Von den vielen Technologien sind Hadoop und MongoDB die beiden beliebten Entscheidungen, wenn es darum geht, Big Data zu speichern und zu verarbeiten. Während beide im Grunde genommen ziemlich ähnlich sind, was sie tun, aber ihre Herangehensweise daran, wie sie es tun, ist ganz anders. Lassen Sie sich einen Blick darauf werfen.
Was ist MongoDB?
MongoDB ist eine Open-Source-Dokumentdatenbank, die mit Millionen von Benutzern die De-facto-NoSQL-Datenbank gewachsen ist, von kleinen Startups bis hin zu Fortune 500-Unternehmen. Führende Unternehmen und Verbraucher -IT -Unternehmen nutzen die Fähigkeiten von MongoDB in ihren Produkten und Lösungen. MongoDB in C ++ geschrieben und ist eine plattformübergreifende, dokumentorientierte Datenbank, die die Einschränkungen von SQL-Schema-basierten Datenbanken effektiv durch Bereitstellung hoher Leistung, hoher Verfügbarkeit und einfacher Skalierbarkeitslösungen angibt. Es handelt sich um eine Datenbank für das moderne Web. Wie andere NoSQL -Datenbanken entspricht MongoDB nicht den Prinzipien von RDBMS ohne Konzepte von Tabellen, Zeilen und Spalten. Es speichert seine Daten in BSON -Dokumenten, in denen alle zugehörigen Daten in einem einzigen Dokument zusammengestellt werden.
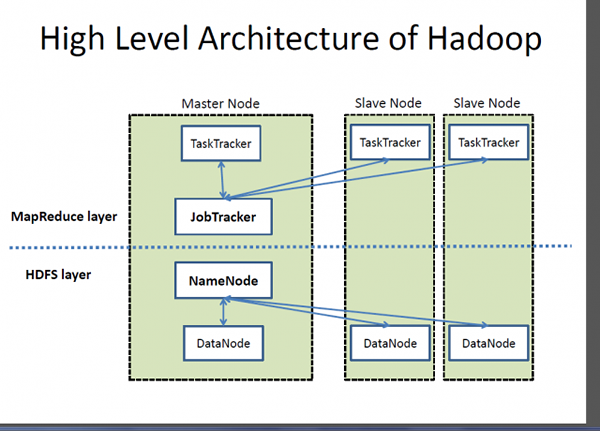
Was ist Hadoop?
Hadoop ist ein Open-Source. Es handelt sich um eine Anwendung, die auf Java basiert und eine Sammlung verschiedener Software, die Datenverarbeitungsframework erstellt. Die Idee ist, große Daten zu angemessenen Kosten in der geringsten Zeit zu verarbeiten. Hadoop besteht aus drei primären Ressourcen: dem Hadoop Distributed File System (HDFS), der MapRece -Programmierungsplattform von Google und dem gesamten Hadoop -Ökosystem. Das Hadoop -Ökosystem besteht aus Modulen, die dazu beitragen. Hadoop MapReduce AIDS -Datenanalyseprozess sehr große Mengen sowohl strukturierter als auch unstrukturierter Daten. Hadoop ist eine eingetragene Marke des Apache -Software Foundaton und MapReduce ist sein Framework für die parallele Verarbeitung.
Unterschied zwischen Hadoop und MongoDB
Plattform
- Während beide als Big Data-Lösungen gelten. MongoDB ist eine Open-Source-Dokumentdatenbank und eine der führenden NoSQL-Datenbanken, die Dokumente anstelle von Zeilen und Tabellen verwendet, um sie flexibel, skalierbar und schnell zu machen. Hadoop hingegen ist ein Open-Source-Framework, das für die Speicherung und Verarbeitung massiver Datenvolumina über Computercomputern entwickelt wurde. Hadoop soll nicht die vorhandenen RDBMS -Systeme ersetzen. Tatsächlich fungiert es als Ergänzung zur Unterstützung des Datenanalyseprozesses großer Volumina sowohl der strukturierten als auch der unstrukturierten Daten.
Die Architektur
- Das Hadoop -Ökosystem ist eine Sammlung von Tools, die neben der MapReduce -Programmierungsplattform von Google und HDFs (Hadoop Distributed Dateisystem) Daten verwenden oder sitzen, um Daten zu speichern und zu organisieren und die Maschinen zu verwalten, die Hadoop ausführen. HDFS ist für den Streaming von Datenzugriff ausgelegt. MongoDB hingegen bietet einen anderen Ansatz; Es basiert auf der Nexus -Architektur, die die Fähigkeiten von NoSQL nutzt und gleichzeitig die Grundlage für relationale Datenbanken beibehält. Es speichert Daten als Dokumente in der binären Darstellung namens BSON (Binary JSON), in denen sie typischerweise als Sammlungen organisiert sind.
Stärke
- Die größte Stärke von Hadoop ist MapReduce. Heute ist Hadoop das beste MapReduce -Framework auf dem Markt. Das Konzept hinter MapReduce ist, dass die Eingabe in logische Stücke aufgeteilt werden kann, wobei jeder Stück unabhängig von einer Kartenaufgabe verarbeitet werden kann. Eine Kartenaufgabe kann auf jedem Rechenknoten im Cluster ausgeführt werden, und mehrere Kartenaufgaben können parallel über den Cluster ausgeführt werden. MongoDB hingegen ist eine Dokumentdatenbank, in der Lasten von Start -up. MongoDB hat sich von einer Nischendatenbanklösung für die De -facto -NoSQL -Datenbank entwickelt. Es ist wirklich ausdrucksstark und flexibel.
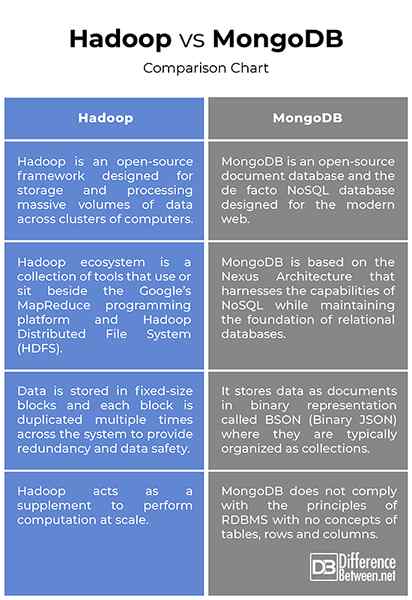
Hadoop vs. MongoDB: Vergleichstabelle
Zusammenfassung
Während beide im Grunde genommen ziemlich ähnlich sind, was sie tun, aber ihre Herangehensweise daran, wie sie es tun, ist ganz anders. MongoDB speichert Daten als Dokumente in der binären Darstellung namens BSON, während in Hadoop die Daten in Blöcken fester Größe gespeichert werden und jeder Block mehrmals über das System dupliziert wird. Das Hadoop -Ökosystem ist eine Sammlung von Tools, die neben der MapReduce -Programmierungsplattform von Google verwenden oder sitzen, während MongoDB auf der Basis der Nexus -Architektur die Fähigkeiten von NOSQL basiert und gleichzeitig die Grundlage für relationale Datenbanken aufrechterhält.