

Unterschied zwischen Hadoop und SQL
- 3597
- 1057
- Fr. Fine Zschunke
Der Begriff "Big Data" ist eines der heißesten Schlagworte in der heutigen digitalen Ära. Jedes Unternehmen, das von kleinen Startups bis hin zu großen Unternehmen reichen, hat Geld für Big Data. Plötzlich sehen wir die Konvergenz erheblicher Trends, die die Branche grundlegend verändern, und es gibt eine Explosion von Daten, da zunehmend die Anzahl von im Internet verbundenen Geräten ist. Big Data ist genau dort, wo der Open-Source-Framework Hadoop zum Bild kommt. Hadoop bietet einen Rahmen für das Speichern und Abrufen großer Datenmengen für Verarbeitung und analytische Zwecke. Aber wie sich Hadoop von anderen Datenbankverwaltungssystemen wie dem SQL -Server unterscheidet? Wir unterstreichen einige wichtige Unterschiede zwischen SQL und Hadoop.
Was ist Hadoop?
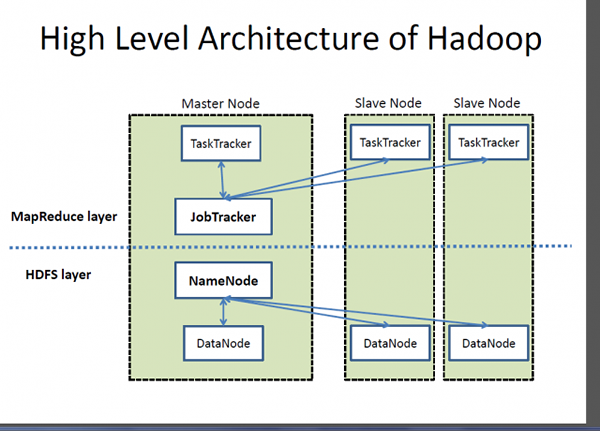
Hadoop ist ein Open-Source-Verteilungsrahmen, das die Anforderungen von Webunternehmen entspricht, um massive Datenmengen zu indexieren und zu verarbeiten, mit freundlicher Genehmigung des zunehmenden Anstiegs von im Internet fähigen Geräten und der nächsten großen Evolution namens Social Media. Google bietet die Inspiration für die Entwicklung, die als Hadoop bekannt wurde. Es bietet ein Framework, mit dem massive Datenmengen verarbeitet werden können, um einen einfachen Zugriff zu gewährleisten und Daten dynamisch zu laden.
Was ist SQL?
SQL war das allgegenwärtige Tool, um auf Daten in einer Datenbank zuzugreifen und zu manipulieren. SQ Server ist kein reguläres Datenbankverwaltungssystem mehr, das von Entwicklern und Datenbankadministratoren und Analysten verwendet wird. Es ist ein großes Ökosystem von Differenztools und -diensten, die zusammenarbeiten, um sehr komplexe Datenplattform -Management -Aufgaben zu liefern. Es ist die De -facto -Sprache für Transaktions- und Entscheidungsunterstützungssysteme und Business Intelligence -Tools, um auf AD -Abfrage auf eine Vielzahl von Datenquellen zuzugreifen. Tatsächlich übernimmt SQL Server die Durchsetzung der Datenqualität und -konsistenz als Hadoop.
Unterschied zwischen Hadoop und SQL
Werkzeug
- Hadoop ist ein Projekt von Apache Software Foundation und ein Open-Source-Rahmen für verteilte Verarbeitungssoftware zum Speichern und Verarbeitung massiver Dateneinstriche und Ausführung von Anwendungen auf Cluster von Commodity-Hardware. Hadoop bietet einen Framework, mit dem massive Datenmengen verarbeitet werden können, um einen einfachen Zugriff zu gewährleisten und Daten dynamisch laden. SQL, kurz für die strukturierte Abfragesprache, hingegen ist die De -facto. SQL war das allgegenwärtige Tool, um Daten in einer Datenbank zuzugreifen, zu manipulieren und zu speichern.
Rahmen von Hadoop vs. Sql
- Im Kern des Hadoop -Ökosystems stehen zwei primäre Komponenten - das Hadoop Distributed Datei System (HDFS) - ein in Java geschriebenes verteiltes, skalierbares und tragbares Dateisystem, um sehr große Datensätze über Computercomputern hinweg zu speichern. und ein Ansatz zur verteilten Verarbeitung basierend auf Java namens MapReduce. SQL Server hingegen ist ein relationales Datenbankverwaltungssystem und eine der weltweit leistungsstärksten Datenplattformen, die von einer Reihe von kommerziellen und internen Produkten zur Abfrage, Manipulation und Visualisierung einer Vielzahl von Datenquellen verwendet werden.
Datentyp
- Hadoop ist so konzipiert, dass er mit einem beliebigen Datentyp arbeitet, unabhängig davon. SQL hingegen ist eine Programmiersprache, die speziell für die Verwaltung und Abfrage von Daten in relationalen Datenbankverwaltungssystemen (RDBMS) erstellt wurde und abfragt. Es basiert auf dem Entitätsbeziehungsmodell der RDBMs, sodass es nur strukturierte Daten verarbeiten kann. SQL kann nicht für unstrukturierte Daten verwendet werden, da sie kein Datenmodell ohne leicht identifizierbare Struktur entsprechen.
wird bearbeitet
- Das HDFS ist ein verteiltes Dateisystem, das die Stapelverarbeitung von Datenbedeutungen unterstützt, die in Stapeln gesammelt werden, und jede Stapel wird zur Verarbeitung gesendet. Die Charge kann von einem Tag bis zu einer Minute alles sein. Da es für die Batch -Verarbeitung ausgelegt ist, hat es nicht das Konzept von zufälligen Lesevorgängen oder Schreibungen. SQL Server im Gegenteil als allgemeine Datenbankplattform unterstützt die Echtzeit-Datenverarbeitung. Dies bedeutet, dass Daten vom Absender zum Empfänger gestreamt werden.
Leistung von Hadoop und SQL
- Die Architektur von Hadoop führt manchmal zu einer Impedanz -Nichtübereinstimmung zwischen Datenspeicherung und Datenzugriff. Es hat weniger Einschränkungen oder Validierungen für die Daten, die es speichert. SQL Server dagegen übernimmt die Durchsetzung der Datenqualität und -konsistenz als Hadoop, die es ihm ermöglicht, das Ökosystem der SQL -basierten Datenanalyse- und Datenvisualisierungstools zu nutzen. SQL verfügt jedoch auch über einige Nachteile, die Skalierbarkeit für die Behandlung massiver Datenmengen und Unterstützung für das Speichern locker formatierter Daten umfassen.
Hadoop vs. SQL: Vergleichstabelle

Zusammenfassung von Hadoop vs. Sql
Hadoop ist das bevorzugte und am häufigsten akzeptierte Big -Data. Aber wenn es um RDBMS geht, ist SQL vielleicht das leistungsstärkste, in Memory und dynamische Datenspeicherung und -managementsystem. Bestehende RDBMS. Wie bei vielen Plattformen haben Hadoop und SQL Server beide einen angemessenen Anteil an Stärken und Schwächen. Verwenden Sie beide zusammen und Sie können die Stärken der einzelnen Nutzung nutzen und gleichzeitig die Schwächen mildern.
- « Unterschied zwischen Spracherkennung und natürlicher Sprachverarbeitung
- Unterschied zwischen Biosensor und Biochip »