

Unterschied zwischen Hadoop und Funken
- 2604
- 599
- Kurt Reinelt
Eines der größten Probleme in Bezug auf Big Data ist, dass viel Zeit für die Analyse von Daten aufgewendet wird, darunter die Identifizierung, Reinigung und Integration von Daten. Die großen Datenmengen und die Anforderung, die Daten zu analysieren, führen zur Datenwissenschaft. Oft sind die Daten jedoch über viele Geschäftsanwendungen und -systeme verteilt, die sie etwas schwierig machen, um zu analysieren. Daher müssen die Daten überarbeitet und neu formatiert werden, um die Analyse zu erleichtern. Dies erfordert ausgefeiltere Lösungen, um Informationen für Benutzer zugänglicher zu machen. Apache Hadoop ist eine solche Lösung, die zum Speichern und Verarbeitung von Big Data zusammen mit einer Vielzahl anderer Big -Data -Tools, einschließlich Apache Spark, verwendet wird. Aber welches ist der richtige Rahmen für die Datenverarbeitung und -analyse - Hadoop oder Spark? Lass es uns herausfinden.
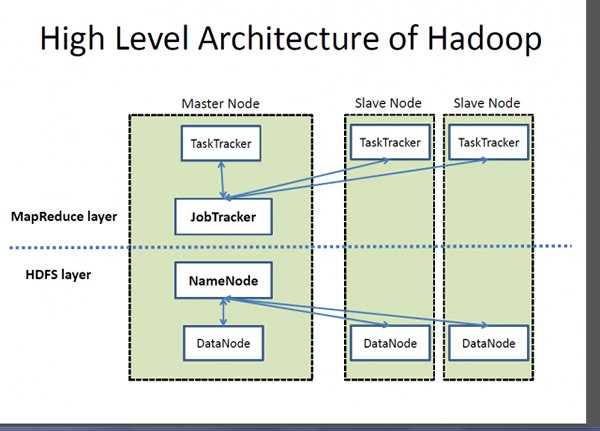
Apache Hadoop
Hadoop ist eine eingetragene Marke von Apache Software Foundation und ein Open-Source. Es behandelt sehr große Daten zu angemessenen Kosten in einer angemessenen Zeit. Darüber hinaus bietet es auch Mechanismen zur Verbesserung der Berechnungsleistung im Maßstab. Hadoop bietet ein Rechenrahmen, um Big Data mithilfe des MapReduce -Programmiermodells von Google zu speichern und zu verarbeiten. Es kann mit Single Server funktionieren oder skalieren, einschließlich Tausende von Rohstoffmaschinen. Obwohl Hadoop im Rahmen eines Open-Source-Projekts innerhalb der Apache-Software-Stiftung basierend auf MapReduce Paradigm entwickelt wurde, gibt es heute eine Vielzahl von Verteilungen für Hadoop. MapReduce ist jedoch immer noch eine wichtige Methode zur Aggregation und Zählung. Die Grundidee, auf der MapReduce basiert, ist die parallele Datenverarbeitung.

Apache Funken
Apache Spark ist eine Open-Source-Cluster-Computing-Engine und eine Reihe von Bibliotheken für die Datenverarbeitung in großem Maßstab auf Computerclustern. Spark ist auf dem Hadoop MapReduce-Modell aufgebaut und ist die am aktivsten entwickelte Open-Source-Engine, um die Datenanalyse schneller zu machen und Programme schneller laufen zu lassen. Es ermöglicht Echtzeit- und erweiterte Analysen auf der Apache Hadoop-Plattform. Der Kern von Spark ist eine Computing -Engine, die aus Planung, Verteilungs- und Überwachungsanwendungen besteht, die aus vielen Computeraufgaben bestehen. Das wichtigste Fahrziel ist es, eine einheitliche Plattform zum Schreiben von Big Data -Anwendungen anzubieten. Spark wurde ursprünglich im APM Laboratory der University of Berkeley geboren und ist jetzt eines der besten Open-Source-Projekte im Rahmen des Portfolios der Apache-Software-Stiftung. Die beispiellosen Funktionen in Memory Computing ermöglichen es analytischen Anwendungen, auf Apache Spark bis zu 100-mal schneller zu laufen als andere ähnliche Technologien auf dem Markt heute.
Unterschied zwischen Hadoop und Funken
Rahmen
- Hadoop ist eine eingetragene Marke von Apache Software Foundation und ein Open-Source. Grundsätzlich handelt es sich. Apache Spark ist eine Open-Source-Cluster-Computing-Engine, die oben auf dem MapReduce-Modell des Hadoop-Modells für die Verarbeitung und Analyse von Daten in großem Maßstab auf Computerclustern aufgebaut ist. Spark ermöglicht Echtzeit und erweiterte Analysen auf der Apache Hadoop-Plattform, um den Hadoop-Computerprozess zu beschleunigen.
Leistung
- Hadoop ist in Java geschrieben, daher erfordert das Schreiben langer Codezeilen, die mehr Zeit für die Ausführung des Programms benötigen. Die ursprünglich entwickelte Hadoop MapReduce -Implementierung war innovativ, aber auch ziemlich begrenzt und auch nicht sehr flexibel. Apache Spark hingegen ist in einer prägnanten, eleganten Scala -Sprache geschrieben, damit die Programme einfacher und schneller laufen können. Tatsächlich ist es in der Lage, Anwendungen bis zu 100 -mal schneller auszuführen als nicht nur Hadoop, sondern auch andere ähnliche Technologien auf dem Markt.
Benutzerfreundlichkeit
- Hadoop MapReduce -Paradigma ist innovativ, aber ziemlich begrenzt und unflexibel. MapReduce -Programme werden in Stapel durchgeführt und sind nützlich für die Aggregation und das Zählen in großem Maßstab. Spark hingegen liefert konsistente, komponierbare APIs, mit denen eine Anwendung aus kleineren Teilen oder aus vorhandenen Bibliotheken herausgebracht werden kann. Die APIs von Spark's APIs sind auch so konzipiert, dass sie eine hohe Leistung ermöglichen, indem sie in den verschiedenen Bibliotheken und Funktionen in einem Benutzerprogramm optimiert werden. Und da Spark dank RDD (Resilient Distributed Dataset) die meisten Eingabedaten im Speicher spricht.
Kosten
- Das Hadoop -Dateisystem (HDFS) ist eine kostengünstige Möglichkeit, große Datenmengen sowohl strukturiert als auch unstrukturiert an einem Ort für die tiefe Analyse zu speichern. Hadoops Kosten pro Terabyte sind viel geringer als die Kosten anderer Datenmanagementtechnologien, die häufig zur Aufrechterhaltung von Unternehmenslager für Unternehmen verwendet werden. Spark hingegen ist bei der Kosteneffizienz nicht gerade eine bessere Option.
Hadoop vs. Spark: Vergleichstabelle

Zusammenfassung von Hadoop vs. Funke
Hadoop ist nicht nur eine ideale Alternative, um große Mengen strukturierter und unstrukturierter Daten auf kostengünstige Weise zu speichern, sondern bietet auch Mechanismen zur Verbesserung der Berechnungsleistung im Maßstab. Obwohl es ursprünglich als Open -Source -Apache -Software -Foundation -Projekt basierend auf dem MapReduce -Modell von Google entwickelt wurde, gibt es für Hadoop heute verschiedene Verteilungen zur Verfügung. Apache Spark wurde auf dem MapReduce -Modell aufgebaut, um seine Effizienz zu erweitern, um mehr Berechnungsarten zu verwenden, einschließlich Stream -Verarbeitung und interaktiven Abfragen. Spark ermöglicht Echtzeit und erweiterte Analysen auf der Apache Hadoop-Plattform, um den Hadoop-Computerprozess zu beschleunigen.