

Unterschied zwischen Fog Computing und Edge Computing

- 2797
- 470
- Leonhard Lesch
Internet of Things (IoT) wurde als nächste große Entwicklung nach dem Internet ausgegeben, das verspricht, unser Leben zu verändern, indem sie die physischen Einheiten auf allgegenwärtige Weise mit dem Internet verbinden. Die IoT -Geräte sind überall um uns herum, die tragbare Geräte, intelligente Autos und Smart -Home -Systeme verbinden. Tatsächlich legen Studien nahe, dass die Rate, mit der sich diese Geräte in unser Leben integrieren, erwartet wird, dass mehr als 50 Milliarden Geräte bis 2020 mit dem Internet verbunden werden. Bisher besteht die grundlegende Nutzung des Internets darin, Computermaschinen mit Maschinen zu verbinden und gleichzeitig in Form von Webseiten zu kommunizieren. Aber IoT geht noch einen Schritt weiter.
Um eine solche massive Anzahl angeschlossener Geräte auszusetzen und den massiven Zustrom von Daten, die von jedem Gerät gesammelt werden, effizient zu verwalten, ist jedoch eine skalierbare Architektur erforderlich. Darüber hinaus ist die Mehrheit der Geräte, aus denen das Internet der Dinge besteht, eine Ressourcenbeschränkung. Ressourcen wie Bandbreite und Speicher sowie Rechenleistung sind knapp. Solche Herausforderungen können gemindert werden, indem die Funktionen von Cloud -Computing näher an den IoT -Geräten erweitert werden. Fog Computing, auch als Edge Computing bezeichnet. Aber was sind diese beiden Technologien und wie sie sich voneinander unterscheiden??
Was ist Fog Computing?
Der Begriff Fog Computing wurde von Cisco geprägt und als Erweiterung des Cloud -Computing -Paradigmas vom Kern des Netzwerks bis zum Rand des Netzwerks definiert. Fog Computing ist eine Zwischenschicht, die die Cloud-Schicht erweitert, um Computer-, Netzwerk- und Speichergeräte näher an die Endnoten in IoT zu bringen. Die Geräte am Rand werden als Nebelknoten bezeichnet und können neben der Eisenbahnstrecke, Verkehrscontrollern, Parkuhren oder woanders überall mit Netzwerkkonnektivität eingesetzt werden. Es ist eine Erweiterung des Cloud -Computing, nicht als Ersatz. Es reduziert die Latenz und überwindet die Sicherheitsprobleme beim Senden von Daten an die Cloud. Aufgrund der engen Integration in die Endgeräte verbessert es die Effizienz des Gesamtsystems und verbessert damit die Leistung kritischer Cyber-Physical-Systeme.
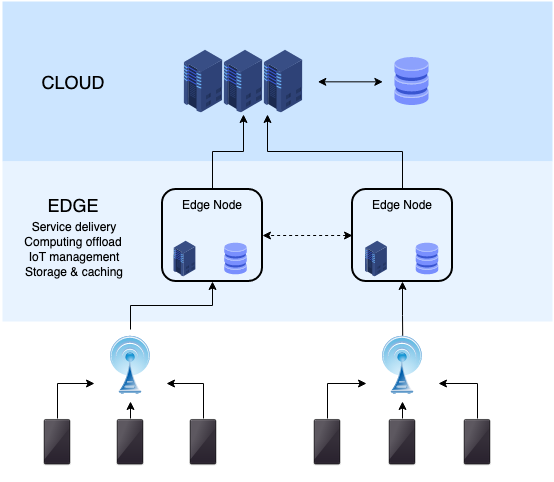
Was ist Edge Computing?
Die Hauptziele von Edge Computing und Fog Computing sind jedoch gleich - dh die Verringerung der Netzwerküberlastung und die Verringerung der End -to -End -Verzögerung -, unterscheiden sie sich jedoch darin, wie sie die Daten verarbeiten und umgehen und wo die Intelligenz- und Rechenleistung platziert werden. Edge Computing ist eine Architektur, die Endbenutzer-Clients und eine oder mehrere Nahverwenner-Edge-Geräte gemeinsam nutzt, um die Recheneinrichtung in Richtung Datenquellen zu übertragen, e.G, Sensoren, Aktuatoren und mobile Geräte. Es drückt die Computerinfrastruktur in die Nähe der Datenquelle, und die Computerkomplexität steigt auch entsprechend an. In einer solchen Architektur kann jedes Gerät mit Rechen-, Speicher- und Networking-Funktionen als Nahverzinsungsrandvorrichtung dienen. In der Regel werden Edge -Ressourcen auf Ad -hoc -Weise konfiguriert, um die Gesamtsystemleistung zu verbessern.
Unterschied zwischen Fog Computing und Edge Computing
Konzept
- Die Hauptziele von Edge Computing und Fog Computing sind jedoch gleich - dh die Verringerung der Netzwerküberlastung und die Verringerung der End -to -End -Verzögerung -, unterscheiden sie sich jedoch darin, wie sie die Daten verarbeiten und umgehen und wo die Intelligenz- und Rechenleistung platziert werden. Beide Begriffe werden häufig austauschbar verwendet, da beide darin bestehen, Intelligenz und Verarbeitungsleistung in die Daten zu bringen, wo die Daten erstellt werden. Fog Computing drückt Intelligenz auf die lokale Netzwerknetzheit der Netzwerkarchitektur, während Daten in einem Nebelknoten oder dem IoT -Gateway verarbeitet werden. Edge Computing gibt die Intelligenz und Leistung des Edge -Gateways in die Geräte wie programmierbare Automatisierungscontroller ein.
Datenkommunikation
- Bei FOG Computing erfordert die Datenkommunikation zwischen den Datengenerierungsgeräten und der Cloud -Umgebung eine Reihe von Schritten. Die Kommunikation wird zunächst an die E/O -Punkte eines PAC gerichtet. Die Daten werden dann an einen Nebelknoten lokaler Netzwerk übertragen, wonach die Daten zur Speicherung in die Cloud gerichtet sind. Im Edge Computing hingegen ist die Kommunikation viel einfacher und es gibt möglicherweise weniger Fehlerpunkte.
Die Architektur
- Fog Computing ist eine dezentrale Computerinfrastruktur, die Cloud-Computing und -Dienste auf den Rand des Netzwerks erweitert, um Computer-, Netzwerk- und Speichergeräte näher an den Endnoten in IoT zu bringen. Ziel ist es, die Effizienz zu verbessern und die Menge an Daten zu verringern, die zur Verarbeitung, Analyse und Speicherung in die Cloud transportiert werden. Edge Computing hingegen ist ein älterer Ausdruck, der vor dem Nebel -Computing -Term liegt. Es ist eine Architektur, die Endbenutzer-Clients und eine oder mehrere Nahverwenner-Edge-Geräte gemeinsam nutzt, um die Recheneinrichtung in Richtung Datenquellen zu übertragen, e.G, Sensoren, Aktuatoren und mobile Geräte.
Fog Computing vs. Edge Computing: Vergleichstabelle

Zusammenfassung
Kurz gesagt, Fog Computing und Edge Computing werden häufig zur gleichen Architektur verwendet, und daher werden die Begriffe als austauschbar angesehen. Es kann jedoch eine subtile Unterscheidung getroffen werden. Obwohl beide eine potenzielle Lösung bieten, die die Wolkenschicht so erweitert, dass sie den Dingen näher kommen, die Daten erzeugen und konsumieren. In Fog Computing befindet sich die Intelligenz im örtlichen Netzwerk, wo wie in Edge Computing die Intelligenz und die Leistung des Edge -Gateways in intelligenten Geräten wie programmierbaren Automatisierungscontrollern befinden.