

Unterschied zwischen Elasticsearch und Hadoop
- 1983
- 117
- Hugo Poehn
ElasticSearch ist eine skalierbare, dokumentorientierte Suchmaschine, die in Lucene aufgebaut ist, um alle Arten der Suche (einschließlich Volltextsuche) und Analytics zu vereinfachen. Elasticsearch ist nicht nur eine Suchmaschine, sondern ist ein verteiltes, merten Dokumentgeschäft mit mehreren Mietern. Hadoop ist ein verteilt.
Was ist Elasticsarch?
ElasticSearch ist eine hochkarätige, verteilte Volltext-Suche und analytische Engine, mit der Sie große Datenmengen in nahezu Echtzeit speichern, suchen und analysieren können. Obwohl es als Volltext-Suchmaschine begann, beginnt es sich als analytische Engine zu entwickeln, die komplexe Aggregationen unterstützen kann. Es ist auf Lucene, einer Suchmaschinen -Software -Bibliothek, die vollständig in Java geschrieben wurde und von der Apache Software Foundation unterstützt wird. Apache Lucene ist eine der am häufigsten verwendeten Bibliotheken für die Suche. Elasticsearch ist in der Natur verteilt und ist sehr einfach zu bedienen, was es einfach macht, loszulegen und zu skalieren, da Sie mehr Daten haben. Obwohl es hauptsächlich als Suchmaschine verwendet wird, kann es als Analyse -Framework über sein leistungsstarkes Aggregationssystem und die Datenspeicherung verwendet werden.
Was ist Hadoop?
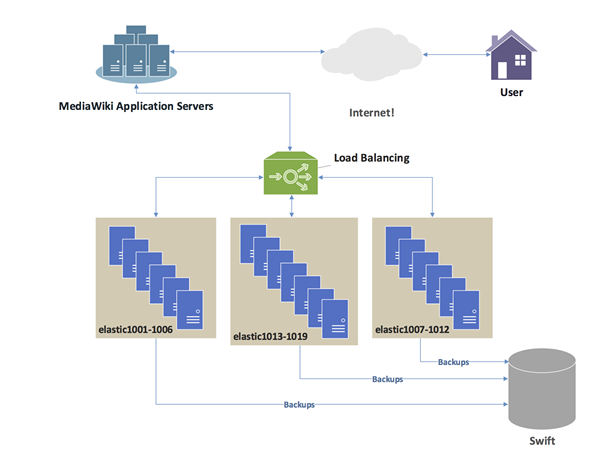
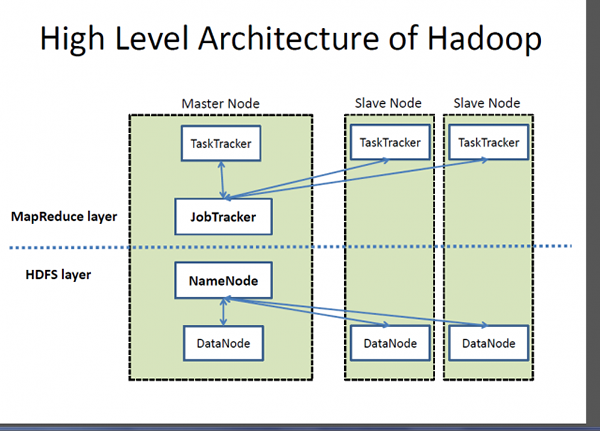
Hadoop ist ein sehr skalierbares, verteiltes Verarbeitungsframework für die Verwaltung der Datenverarbeitung und Speicherung großer Datensätze, die in Cluster -Systemen ausgeführt werden. Hadoop ist eine Sammlung von Software -Dienstprogrammen, mit der das Speichern und Verarbeitung von Big Data und die Ausführung von Anwendungen von Rohstoffhardwareclustern ermöglicht werden kann. Hadoop ist die eingetragene Marke der Apache Software Foundation, die als einzelnes Softwareprojekt zur Unterstützung einer Web -Suchmaschine begann, sich jedoch zu einem Ökosystem von Tools und Anwendungen entwickelt hat, die zur Analyse eines großen Datenvolumens verwendet wurden. Hadoop basiert auf dem MapReduce -Programmiermodell für die Verarbeitung großer Datensätze auf Cluster von Commodity -Hardware. Die Kernkomponente von Hadoop ist das Hadoop Distributed Dateisystem (HDFS), ein Hochleistungs-Parallel-Dateisystem, der die Anforderungen der Big-Data-Verarbeitung erfüllt, wie z. B. Streaming-Zugriff auf Blocks.
Unterschied zwischen Elasticsearch und Hadoop
Werkzeug
- ElasticSearch ist eine hochkarätige, verteilte Volltext-Suche und analytische Engine, mit der Sie große Datenmengen in nahezu Echtzeit speichern, suchen und analysieren können. Obwohl es hauptsächlich als Suchmaschine verwendet wird, kann es als Analyse -Framework über sein leistungsstarkes Aggregationssystem und die Datenspeicherung verwendet werden. Hadoop hingegen ist ein leistungsstarkes verteiltes Verarbeitungsframework, das als einzelnes Softwareprojekt zur Unterstützung einer Web -Suchmaschine begann, sich jedoch zu einem Ökosystem von Tools und Anwendungen entwickelt hat, die zur Analyse eines großen Datenvolumens verwendet wurden.
Die Architektur
- Hadoop ist ein Open-Source-Software-Framework, das eine Master-Slave-Architektur für die Datenspeicherung und die Datenverarbeitung unter Verwendung des Hadoop Distributed Dateisystems (HDFS) bzw. MapRece-Programmiermodell befolgt. HDFS ist ein Hochleistungs-Parallel-Dateisystem, das den Anforderungen der Big-Data-Verarbeitung entspricht. Elasticsearch hingegen basiert auf der REST -Architektur und bietet API -Endpunkt. Auf diese Weise können Sie indizierte Daten auf verschiedene Weise integrieren, verwalten und abfragen.
Prinzip
- Elasticsearch bietet eine vollständige Abfrage -DSL, die auf JSON basiert, um die Kraft von Lucene aufzudecken, um Abfragen auf sehr einfache Weise zu lesen und zu schreiben. Die meisten NoSQL -Datenspeicher verwenden JSON, um ihre Daten zu speichern, da das JSON -Format sehr prägnant, flexibel und leicht zu verstehen ist. Hadoop hingegen basiert auf dem MapReduce -Programmiermodell für die Verarbeitung großer Datensätze auf Cluster von Commodity -Hardware. MapReduce ist ein Programmierparadigma innerhalb des Hadoop -Framework.
Verwenden
- Elasticsearch ist eine Volltexten -Suchmaschine, die die Hauptverwendung ist, aber auch als Analyse -Framework über sein leistungsstarkes Aggregationssystem verwendet wird. Es kann auch als sehr leistungsstarke analytische Engine verwendet werden, um alle Abfragen auszuführen, die Sie normalerweise in einer Stapel oder Offline in Echtzeit ausführen würden. Es unterstützt nicht nur die Suche, sondern auch komplexe Aggregationen. Hadoop hingegen wird hauptsächlich als Tool zum Speichern von Daten und zum Ausführen von Anwendungen auf Rohstoffhardware mithilfe des weltweit zuverlässigsten Speichersystems HDFs verwendet.
Elasticsearch vs. Hadoop: Vergleichstabelle
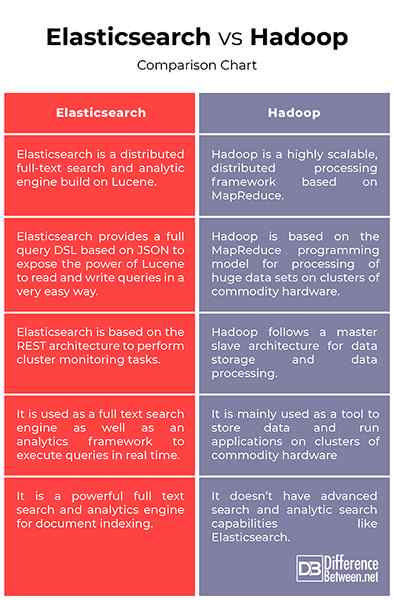
Zusammenfassung von Elasticsearch vs. Hadoop:
Elasticsearch ist ein leistungsstarkes Tool für die Volltextensuche und -dokumentindexierung auf Lucene, einer Suchmaschinensoftware -Bibliothek, die vollständig in Java geschrieben wurde, während Hadoop ein Datenverarbeitungsrahmen für die Behandlung großer Datenmengen in einem Bruchteil von Sekunden ist. Hadoop basiert auf dem beliebten MapReduce -Programmiermodell für die Verarbeitung großer Datensätze auf Cluster von Commodity -Hardware. Elasticsearch ist eine leistungsstarke Analytics -Engine, um Ihre gesamte Analysepipeline zu verwalten, während Hadoop ein Rahmen für die Behandlung einer Datenaggregation oder Transformationsjob ist.
- « Unterschied zwischen Füllstoffen und Botox
- Unterschied zwischen Air National Guard und Air Force Reserve »