

Unterschied zwischen Datenanmerkungen und Kennzeichnung
- 2253
- 433
- Justus Dengler
Unternehmen investieren seit Jahren stark in maschinelles Lernen. In der Tat ist maschinelles Lernen einer der aktivsten Forschungsbereiche im Bereich der künstlichen Intelligenz (KI). Das Hauptziel der Forschung im Bereich des maschinellen Lernens ist es, intelligente, selbstbewusste Maschinen oder Computer zu schaffen, die in der Lage sind, menschliche kognitive Fähigkeiten zu replizieren und selbst Wissen zu erwerben. Das Verständnis des Menschen mit dem Menschen, das gut genug ist, um Aspekte dieses Lernverhaltens in Maschinen zu reproduzieren. Jeden Tag lehrt Menschen Computer, viele neue und aufregende Probleme zu lösen, z.
Trotzdem gibt es so viele Dinge, die Computer nicht tun können, insbesondere im Zusammenhang mit dem Verständnis des menschlichen Verhaltens. Statistische Methoden haben sich als wirksames Mittel erwiesen, um diese Probleme zu erreichen, aber maschinelle Lerntechniken funktionieren besser, wenn die Algorithmen mit Zeigern auf das ausgestattet sind, was in einem Datensatz relevant und bedeutungsvoll ist, und nicht auf große Datenlöser. Im Kontext der natürlichen Sprachverarbeitung kommen diese Zeiger häufig in Form von Anmerkungen - die Kunst, die Daten in verschiedenen Formaten zu kennzeichnen. Datenanmerkungen und Kennzeichnungen sind zwei grundlegende Elemente des maschinellen Lernens, mit denen Maschinen Bilder, Text und Videos erkennen können.
Was ist Datenannotation?
Einfach einen Computer mit massiven Datenbetrag zur Verfügung zu stellen und zu erwarten, dass er das Sprechen lernt, reicht nicht aus. Die Daten müssen so erfasst und präsentiert werden, dass ein Computer Muster und Schlussfolgerungen aus den Daten leicht erkennen kann. Dies geschieht normalerweise durch Hinzufügen relevanter Metadaten zu einer Reihe von Daten. Jedes Metadaten -Tag, mit dem Elemente des Datensatzes markiert werden, wird als Annotation über die Eingabe bezeichnet. In maschinellem Lernen müssen die Daten also kommentiert oder einfach bezeichnet werden, damit das System es leicht erkennen kann. Damit die Algorithmen effektiv und effizient lernen können, muss die Annotation der Daten für den Job, auf den der Computer beauftragt ist. Einfach ausgedrückt, Datenanmerkungen sind die Technik zur Kennzeichnung der Daten, damit die Maschine die Eingabedaten verstehen und auswendig lernen kann.
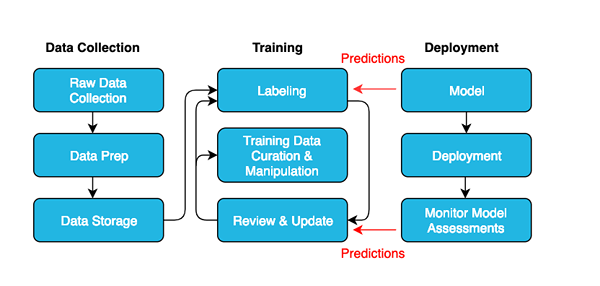
Was ist Datenkennzeichnung?
Die Daten werden in vielen verschiedenen Formen wie Text, Bildern, Audio und Video geliefert. Um die Daten so zu bereichern, dass die Maschine sie durch Algorithmen für maschinelles Lernen erkennen kann, müssen die Daten gekennzeichnet werden. Die Datenkennzeichnung ist, wie der Name schon sagt. Wenn die Daten gekennzeichnet sind, wird sie für das Training fortgeschrittener Algorithmen verwendet, um Muster in Zukunft zu erkennen. Die Beschriftung ist im Grunde genommen das Markieren der Daten oder das Hinzufügen von Metadaten, um sie aussagekräftiger und informativer zu machen, damit Maschinen sie verstehen und daraus lernen können. Zum Beispiel kann ein Etikett angeben, dass ein Bild eine Person oder ein Tier oder eine Audiodatei enthält, in welcher Sprache oder um die Art von Aktion zu bestimmen, die in einem Video ausgeführt wird.
Unterschied zwischen Datenanmerkungen und Kennzeichnung
Bedeutung
- Beide Datenkennzeichnung und Annotation sind die häufig austauschenden Begriffe. Datenanmerkungen sind im Grunde genommen die Technik zur Kennzeichnung der Daten, damit die Maschine die Eingabedaten mithilfe von Algorithmen für maschinelles Lernen verstehen und merken kann. Datenkennzeichnung, auch Daten -Tagging genannt. Die Beschriftung identifiziert eine einzelne Entität aus einem Datensatz von Daten.
Zweck
- Die Kennzeichnung ist ein Eckpfeiler des überwachten maschinellen Lernens und verschiedene Branchen sind immer noch stark auf manuelles Annotieren und Kennzeichnung ihrer Daten angewiesen. Die Beschriftungen werden verwendet, um Datensatzfunktionen für NLP -Algorithmen zu identifizieren, während Datenanmerkungen für visuelle Wahrnehmungsmodelle verwendet werden können. Die Kennzeichnung ist komplizierter als Annotation. Annotation hilft dabei. Beide Prozesse müssen mit absoluter Genauigkeit durchgeführt werden, um sicherzustellen.
Anwendungen
- Datenanmerkungen sind ein grundlegendes Element beim Erstellen von Trainingsdaten für Computer Vision. Annotierte Daten sind erforderlich, um Algorithmen für maschinelles Lernen zu trainieren, um die Welt zu sehen, wie wir Menschen sehen. Die Idee besteht? Die Antwort sind Daten und viele und viele davon. Annotation ist ein Prozess, der in beaufsichtigtem maschinellem Lernen für Trainingsdatensätze verwendet wird, um Maschinen dabei zu helfen. Die Kennzeichnung wird verwendet, um wichtige Merkmale in den Daten zu identifizieren und gleichzeitig die Beteiligung des Menschen zu minimieren. Die realen Anwendungsfälle umfassen NLP, Audio- und Videoverarbeitung, Computervisionen usw.
Datenannotation vs. Datenkennzeichnung: Vergleichstabelle

Zusammenfassung
Annotation ist ein Prozess, der in beaufsichtigtem maschinellem Lernen für Trainingsdatensätze verwendet wird, um Maschinen dabei zu helfen. Die Kennzeichnung wird verwendet, um wichtige Merkmale in den Daten zu identifizieren und gleichzeitig die Beteiligung des Menschen zu minimieren. Die Kennzeichnung ist ein Eckpfeiler des überwachten maschinellen Lernens und verschiedene Branchen sind immer noch stark auf manuelles Annotieren und Kennzeichnung ihrer Daten angewiesen. Da eine schlechte Kennzeichnung zu einer kompromittierten KI führen kann, muss die Kennzeichnung oder Annotation genau durchgeführt werden, damit sie für AI -Anwendungen verwendet werden können.