

Unterschied zwischen Big Data und Hadoop

- 3755
- 199
- Hugo Poehn
Die Beziehung zwischen Big Data und Hadoop ist die wichtigsten Themen, die bei den Anfängern interessiert sind. Und die Unterscheidung zwischen diesen beiden verwandten Konzepten ist ziemlich faszinierend. Big Data ist ein wertvolles Gut, das ohne seinen Handler keine besondere Verwendung hat. Hadoop ist also der Handler, der den besten Wert aus dem Vermögenswert bringt. Schauen wir uns die beiden genau an, gefolgt von den Unterschieden zwischen den beiden.
Was ist ein Big Data?
In der heutigen digitalen Welt sind wir von Daten umgeben. Es würde genügt zu sagen, dass Daten überall sind. Die schnelle Entwicklung des Internets und des Internet of Devices (IoT) und die kontinuierliche Nutzung elektronischer Medien haben zur Geburt von E-Commerce und Social Media geführt. Infolgedessen wurden eine massive Datenmenge generiert und tatsächlich täglich immer noch generiert. Daten haben jedoch keine Nutzung, es sei denn, Sie verfügen über die erforderlichen Fähigkeiten, um sie zu analysieren. Daten in der aktuellen Form sind Rohdaten, von denen der größte Teil von Benutzerninhalten ist, der analysiert und gespeichert werden muss. Daten werden aus mehreren Quellen von sozialen Medien bis hin zu eingebetteten/sensorischen Systemen, Maschinenprotokollen, E-Commerce-Websites usw. generiert. Die Verarbeitung einer solchen wahnsinnigen Datenmenge ist eine Herausforderung. Big Data ist ein Dachbegriff, der sich auf die vielen Möglichkeiten bezieht, wie Daten systematisch verwaltet und auf einem so großen Maßstab verarbeitet werden können. Big Data bezieht sich auf große, komplexe Datensätze, die zu kompliziert sind, um durch herkömmliche Datenverarbeitungsanwendungen analysiert zu werden.
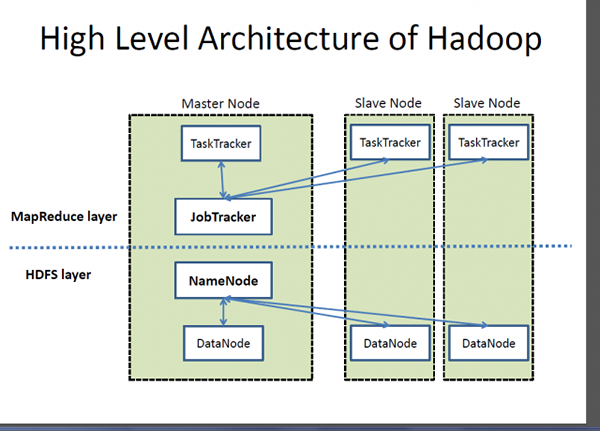
Was ist ein Hadoop?
Wenn Big Data ein sehr wertvolles Kapital ist, ist Hadoop ein Programm oder ein Tool, um den besten Wert aus diesem Vermögenswert herauszubringen. Hadoop ist ein Open-Source-Software-Dienstprogramm, das entwickelt wurde, um das Problem der Speicherung und Verarbeitung großer, komplexer Datensätze zu behandeln. Apache Hadoop ist wahrscheinlich eines der beliebtesten und am häufigsten verwendeten Software -Framework, das zum Speichern und Verarbeiten von Big Data verwendet wird. Es ist ein vereinfachtes Programmiermodell, mit dem Sie verteilte Systeme und seine automatische und wirtschaftliche Verteilung des Wissens über eine Ware von Cluster -Servern bequem schreiben und überprüfen können. Was Hadoop unverwechselbar macht, ist seine Fähigkeit, von einem einzelnen Server auf Tausende von Rohstoffserverautomaten zu skalieren. Einfach ausgedrückt, Apache Hadoop ist das De -facto -Software -Framework zum Speichern und Verarbeiten einer großen Datenmenge, was oft als Big Data bezeichnet wird. Zwei Schlüsselkomponenten des Hadoop -Ökosystems sind Hadoop Distributed Dateisystem (HDFS) und MapReduce -Programmiermodell.
Unterschied zwischen Big Data und Hadoop
Grundlagen
- Big Data und Hadoop sind die beiden bekanntesten Begriffe, die eng miteinander verbunden sind, so dass Big Data ohne Hadoop keine Bedeutung oder Wert haben würde. Stellen Sie sich Big Data als einen tiefen Wertvermögen vor. Apache Hadoop ist also ein Versorgungsprogramm, das den besten Wert aus Big Data herausbringen soll. Big Data bezieht sich auf große, komplexe Datensätze, die zu kompliziert sind, um durch herkömmliche Datenverarbeitungsanwendungen analysiert zu werden. Apache Hadoop ist ein Software -Framework, mit dem das Problem der Speicherung und Verarbeitung großer, komplexer Datensätze behandelt wird.
Konzept
- Daten in seiner Rohform sind nicht nützlich und sehr schwer zu arbeiten, es sei denn. Wir sind von unzähligen Tonnen von Daten umgeben, die wir in dieser digitalen Ära sehen und nutzen. Zum Beispiel haben wir so viele Inhalte auf Social -Media -Websites und Apps wie Twitter, Instagram, YouTube usw. Big Data bezieht sich also auf diese großen Mengen sowohl strukturierter als auch unstrukturierter Daten und der Informationen, die wir aus diesen Daten herausholen können, wie z. B. Muster, Trend. Hadoop ist ein verteiltes Software -Framework, das die Speicherung und Verarbeitung dieser großen Datensätze über eine Ware von Cluster -Servern übernimmt.
Ziel
- Daten in der aktuellen Form sind Rohdaten, von denen der größte Teil von Benutzerninhalten ist, der analysiert und gespeichert werden muss. Datensätze wachsen exponentiell und sie werden außer Kontrolle geraten. Wir brauchen also Möglichkeiten, all diese strukturierten und unstrukturierten Daten zu bewältigen, und wir benötigen ein einfaches Programmiermodell, das die richtigen Lösungen für die Welt der Big Data bietet. Dies erfordert ein großes Rechenmodell im Gegensatz zu den traditionellen Rechenmodellen. Apache Hadoop ist ein verteilt. Es wurde entwickelt, um eine große Datenmenge über die Knoten im Cluster zu verteilen und zu verarbeiten.
Big Data vs. Hadoop: Vergleichstabelle
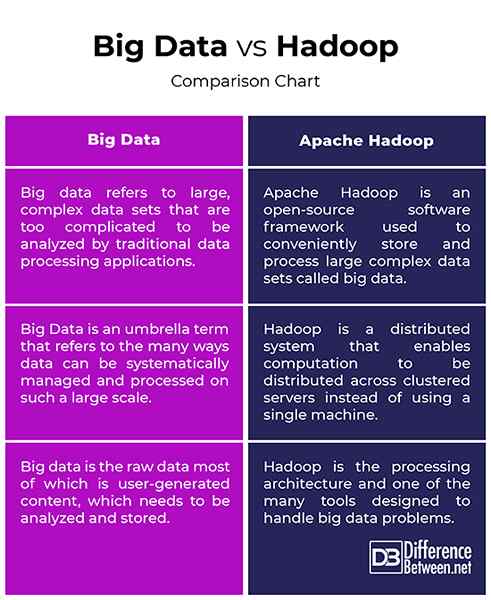
Zusammenfassung von Big Data vs. Hadoop
Big Data ist ein sehr wertvolles Gut, das nicht nützlich ist, es sei denn, wir finden Wege, daran zu arbeiten. Social -Media -Anwendungen wie Twitter, Facebook, Instagram, YouTube usw. sind die Beispiele für Big Data im wirklichen Leben, die den Technologien, die wir heutzutage verwenden, einige Herausforderungen stellt. Diese schnell wachsenden Daten mit unstrukturiertem Inhalt werden üblicherweise als Big Data bezeichnet. Daten in seiner rohen Form sind jedoch sehr schwer zu arbeiten. Wir brauchen Möglichkeiten, diese Daten zu erwerben, zu speichern, zu verarbeiten und zu analysieren, damit wir etwas Nützliches daraus machen können, wie ein Muster oder ein Trend. Hadoop ist das Tool, mit dem diese komplexen Datensätze gespeichert und verarbeitet werden können, die zu groß sind, um mit herkömmlichen Computertechniken und Tools behandelt zu werden.