

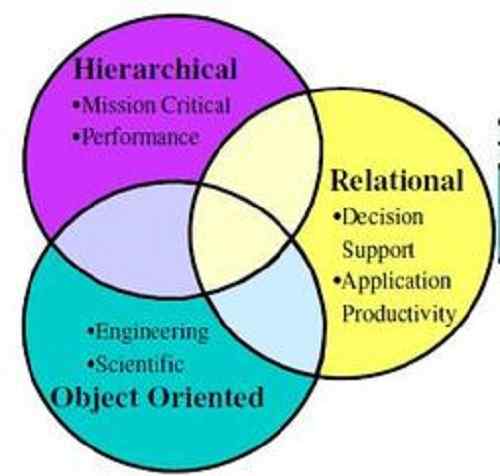
Unterschied zwischen hierarchischer Datenbank und relationaler Datenbank
- 4218
- 235
- Hr. Jeremie Orth
Wir alle wissen, dass Datenbanken für die Umstellung mit Daten und ihrem Speicher gerahmt sind. Außerdem sind wir sogar verwirrt darüber, welche Datenbank zu verwenden ist, da wir viele Optionen für die Auswahl haben! Im Allgemeinen wählen wir den Datenbankanbieter oder den Eigentümer. Außerdem können wir auch die richtige Datenbank für unser Bedürfnis auswählen, indem wir ihre Typen wie hierarchisch, eine relationale, eine Netzwerkdatenbank oder eine objektorientierte Datenbank analysieren.
Was ist eine hierarchische Datenbank?
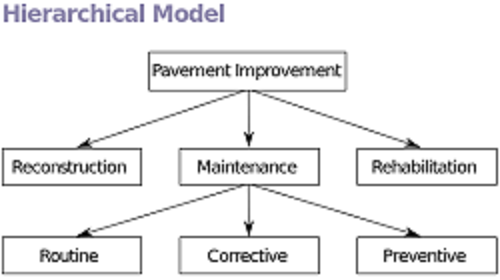
In einer hierarchischen Datenbank sind die Daten in einer Baumstruktur organisiert. Jede einzelne Daten wird in einem Feld und den Feldern wiederum die Formularaufzeichnungen gespeichert. Diese Daten werden mit Hilfe von Verbindungen zwischen ihnen zugegriffen. In dieser Struktur werden alle Datensätze schließlich mit einem einzigen übergeordneten Datensatz verknüpft. Es wird auch als Eigentümeraufzeichnung bezeichnet. Die Verbindungen zwischen den Aufzeichnungen werden häufig als Eltern-Kind-Beziehungen bezeichnet. Die beste Verwendung der hierarchischen Datenbank ist die Bereitstellung in einem Bibliothekssystem, da sie Namen oder Buchnummern mithilfe des Dewey -Dezimalsystems speichert. Dieses System ähnelt einer Baumstruktur, indem sie dieselbe übergeordnete Nummer teilen und anschließend wie Bäume verzweigt. In ähnlicher Weise können wir es verwenden, um Namen in einem Telefonverzeichnis zu speichern.
Was ist eine relationale Datenbank?
Es speichert Daten in Form von Tabellen mit eindeutigen Schlüssel zum Zugriff auf die Daten. Diese Tabellen liefern die Daten mit Hilfe der Verwendung von Abfragsprachen in dem erforderlichen Formular. Der interessante Teil ist, dass keine Daten für die Neugruppe der Daten erforderlich sind, um die Daten unserer Wahl abzurufen. Es wird häufig als relationale Datenbankverwaltungssysteme (RDBMS) bezeichnet.
Unterschiede:
- Einfacher zu verwenden: Die hierarchischen Datenbanken verwenden die logische Eltern-Kind-Beziehung und es sieht auch einfacher aus. Relationale Datenbanken umfassen jedoch Tabellen, um Datensätze in Form von Tabellenfeldern zu speichern. Auch in den meisten Fällen erfordert es für jeden Datensatz einen einzigartigen Schlüssel.
- Das ist älter? Die hierarchischen Datenbanken entstanden bereits vor den relationalen Datenbanken und es ist der Prozessor für alle anderen Datenbanken.
- Der grundlegende Unterschied im Datenbegriff: In hierarchischen Datenbanken wird eine Datenkategorie als "Segmente" bezeichnet, während sie in relationalen Datenbanken als "Felder" bezeichnet wird.
- Nachlass: Jedes untergeordnete Segment/Knoten in einer hierarchischen Datenbank erbt die Eigenschaften seines Elternteils. In relationalen Datenbanken gibt es jedoch kein Konzept der Vererbung, da es keine Datenniveaus gibt.
- Datenverknüpfung: In hierarchischen Datenbanken sind die Segmente implizit mit einem Kind verknüpft mit seinem Elternteil verknüpft. In relationalen Datenbanken sollten wir die Tabellen mithilfe von "Primärschlüssel" und "Fremdschlüssel" ausdrücklich verknüpfen, um die Tabellen ausdrücklich zu verknüpfen, ausdrücklich verknüpfen.
- Verwendung von Schlüsseln: Die relationalen Datenbanken sind im Allgemeinen mit einzigartigen Schlüssel, die als Primärschlüssel bezeichnet werden. Diese Fremdschlüssel sind Primärschlüssel in einer anderen Tabelle und werden beim Zugriff auf die andere Tabelle aus dieser Tabelle verwiesen. Die Hauptverwendung von Schlüsseln besteht also darin, den Datensätzen eine eindeutige Identifizierung zu geben und andere Tabellen während des Datenabrufprozesses zu verweisen. Aber eine hierarchische Datenbank verwendet niemals Schlüssel. Es hat seine Links, um den Pfad zu bezeichnen, der während des Datenabrufs durchquert werden soll. Daher können wir die Schlüssel in relationalen Datenbanken als das Äquivalent der Pfade in hierarchischen Datenbanken während der Datenabrufe betrachten. Die Pfade repräsentieren jedoch nie die Einzigartigkeit von Daten, die in hierarchischen Datenbanken gespeichert wurden.
- Einzigartige und doppelte Daten: Da die Schlüssel die Einzigartigkeit von Daten in relationalen Datenbanken darstellen, können wir solche Daten auf Bedarf problemlos auflisten. Wenn dies jedoch in einer hierarchischen Datenbank erforderlich ist, benötigt es eine Lose -Verarbeitung. Wir können mehr als eine Kopie desselben Buches in einer Bibliothek haben, aber mit verschiedenen Buchnummern zugewiesen werden. In diesem Fall sollten wir die Buchnamen vergleichen, um die Duplikate zu identifizieren. Daher sind relationale Datenbanken geeignet, um eindeutige Daten zu speichern, während hierarchische Datenbanken gute für Daten mit Duplikaten sind.
- Daten abrufen: Stellen Sie sich vor, Sie haben ein Bibliotheksverwaltungssystem und es speichert Buchdetails mit einer zugewiesenen Buchnummer für jedes Buch.
Betrachten Sie ein Buch, das mit der Buchnummer als 1034 zugewiesen ist. Der Datenabrufprozess finden Sie hier unten nur.
- In einer hierarchischen Datenbank:
Wenn Buch-NO> 1000
Wenn Buch-NO> 1500 …
Sonst wenn book-no> 1100
Wenn Buch-NO> 1050 …
Sonst if book-no> 1025 if book-no> 1030 if book-no> 1035 …
Sonst wenn book-no = 1031…
Wenn Buch-no = 1032…
Wenn Buch-no = 1033…
Wenn Buch-no = 1034… Übereinstimmung hier gefunden
Anders
Wenn Buch-NO> 500 …
Anders …
Der obige Vorgang erfolgt Schritt für Schritt, wenn wir einen Zweig des Baumes erreichen, der aus seinem Kofferraum klettern.
- In einer relationalen Datenbank: Hier werden die Daten mit Hilfe der Primärschlüssel und der Fremdschlüssel abgerufen. Nach dem Durchlaufen des Kopfes müssen Sie den Schwanz nicht berühren! Ja, wir können mit seinem passenden Schlüssel direkt auf die erforderlichen Felder zugreifen.
Bedenken Sie, dass wir das Geburtsdatum "Geburtsdatum" holen müssen, dessen Mitarbeiter 12345 beträgt. Hier ist der Mitarbeiter-ID der Hauptschlüssel und wir rahmen Abfragen wie unten ein.
Mitarbeitername, Mitarbeiter-Dob abrufen
Vom Mitarbeitertisch
Wobei Mitarbeiter-ID = '12345' '.
Hier können wir die erforderlichen Felder direkt abrufen und müssen nicht über den Busch schlagen!
- Viele-zu-Viele- oder Eins-zu-Viele-Datenverknüpfungen: Diese Art von Datenlinks sind mit den hierarchischen Datenbanken nicht möglich, da ein Elternteil mehr als 1 Kind haben kann, während ein Kind nicht mehr als 1 Elternteil haben kann. Im letzteren Fall würden wir auf die vielen zu eins- oder viele zu viele Datenverknüpfungen oder Beziehungen stoßen. Diese Art von Datenbeziehungen sind jedoch mit relationalen Datenbanken möglich.
- Die Felder in der relationalen Datenbank gegenüber den Knoten in der hierarchischen Datenbank: In relationalen Datenbanken basiert die Datenklassifizierung auf dem Feld "Feld", während sie in hierarchischen Datenbanken auf den "Knoten oder Segmenten" basiert, die basieren. Jedes Feld ist in jedem Datensatz in relationalen Datenbanken vorhanden. Ebenso können wir jedes Segment in den endgültigen Daten i sehen.e. Buchnummer, Buchname usw. im Fall eines Bibliotheksmanagementsystems. Dies wird oft als grundlegender Unterschied zwischen den beiden Datenbanken bezeichnet, die wir in den Anfangsphasen unseres Artikels erwähnt haben.
- Wo es seine Verwendung findet? Jede Datenbank findet ihre Verwendung in einer Anwendung oder einem System und basiert nur auf den Anforderungen. Zum Beispiel verwenden die Bibliotheksmanagementsysteme ein Dezimalsystem, das die Bücher ähnlich einem Baum nennt. In diesen Systemen funktioniert das RDBMS nicht gut, da sein Konzept unterschiedlich ist. Wenn wir jedoch eine Organisation betrachten, können die Details von Mitarbeitern oder Waren nicht zu einer baumartigen Struktur passen. Daher können Tabellen eine bessere Lösung sein, um solche Details zu speichern. Hier ist die relationale Datenbank also eine bessere Wahl.
Schauen wir uns jetzt die Unterschiede in tabellarischer Form an.
| S.NEIN | Unterschiede in | Hierarchische Datenbank | Relationale Datenbank |
| 1. | Speichermode | Es verwendet eine hierarchische Speicherung von Daten. | Es speichert Daten tabellarisch. |
| 2. | Einfachheit in der Nutzung und Darstellung | Es ist komplex als der andere. | Es sieht sehr einfacher aus, darzustellen und zu verstehen. |
| 3. | Das ist älter? | Es ist älter zum anderen. | Es kam erst nach den hierarchischen Datenbanken. |
| 4. | Der grundlegende Unterschied im Datenbegriff | Die Datenkategorie wird als "Segmente" bezeichnet. | Die Datenkategorie wird als "Felder" bezeichnet. |
| 5. | Nachlass | Jedes Kindersegment/Knoten erbt die Eigenschaften von seinem Elternteil. | Es gibt kein Konzept der Vererbung. |
| 6. | Datenverbinden | Die Segmente sind implizit verbunden, da ein Kind mit seinem Elternteil verbunden ist. | Standardmäßig nicht verknüpft. Wir sollten die Tabellen ausdrücklich mit Hilfe von 'Primärschlüssel' und 'Fremd Keys' verknüpfen.
|
| 7. | Verwendung von Schlüssel | Diese werden mit einzigartigen Schlüssel, die als Primärschlüssel bezeichnet werden. Diese Fremdschlüssel sind Primärschlüssel in einer anderen Tabelle und werden beim Zugriff auf die andere Tabelle aus dieser Tabelle verwiesen. Die Tasten geben den Datensätzen eine eindeutige Identifizierung und verweisen auf andere Tabellen während des Datenabrufprozesses. | Es verwendet niemals Schlüssel. Es hat seine Links, um den Pfad zu bezeichnen, der während des Datenabrufs durchquert werden soll. Daher können wir die Schlüssel in relationalen Datenbanken als das Äquivalent der Pfade in hierarchischen Datenbanken während der Datenabrufe betrachten. Die Pfade repräsentieren jedoch nie die Einzigartigkeit von Daten, die in hierarchischen Datenbanken gespeichert wurden.
|
| 8. | Einzigartige und doppelte Daten | Eindeutige Daten können leicht abgerufen werden, da sie ohne Duplikate in Bezug auf den Primärschlüssel gespeichert sind. | Es benötigt etwas mehr Verarbeitung, um die eindeutigen Daten zu holen. |
| 9. | Daten abrufen | Die Daten werden von den meisten Knoten abgerufen und dann entlang der Pfade überquert, bis der erforderliche Knoten oder Segment erreicht ist. | Die Daten werden mit Hilfe der Schlüssel aus den Tabellen abgerufen. |
| 10. | Viele-zu-Viele- oder Eins-zu-Viele-Datenverbinden | Eine solche Verknüpfung ist hier nicht möglich, da ein Elternteil viele Kinder haben kann und nicht das umgekehrte i.e. Ein Kind kann nicht viele Eltern haben. Daher sind viele zu viele oder eins-zu-viele-Datenverknüpfungen überhaupt nicht möglich. | Diese Art von Datenbeziehungen sind hier möglich. |
| 11. | Felder gegen Knoten | Die Datenklassifizierung basiert auf dem 'Segment oder Knoten' | Die Datenklassifizierung basiert auf dem Feld "Feld" |
| 12. | Wo es seine Verwendung findet? | In hierarchischen Strukturen wie dem Bibliotheksverwaltungssystem, um Mitarbeiterbezeichnungen von CEO zu Mitarbeitern zu speichern, usw | In Strukturen, die leicht als Tabellen wie die Speicherung von Mitarbeiterndetails usw. dargestellt werden können, usw. |
In diesem Artikel können Sie eine Vorstellung davon machen, wie sich die hierarchischen und die relationalen Datenbanken unterscheiden. Wenn Sie sich immer noch verwirrt fühlen, teilen Sie es uns bitte mit!