

Unterschied zwischen Hadoop und Teradata
- 3306
- 188
- Kurt Reinelt
Mehr denn je spielt die Technologie eine entscheidende Rolle im gesamten Prozess, in dem wir Daten sammeln und verwenden. Die Technologie hat die Art und Weise verändert, wie Daten erzeugt, verarbeitet und konsumiert werden. Da der Markt für Big Data Analytics rasch expandiert, beginnen viele Unternehmen und Unternehmen, in Big Data -Technologien zu investieren, um diese massiven Datenmengen zu speichern und zu analysieren. Heute gibt es viele Big Data -Technologien auf dem Markt, die sich auf die neuen Technologiestapel für den Umgang mit Big Data auswirken. Eine solche Technologie, die im Zentrum der Big Data -Gespräche stand, ist Apache Hadoop. Hadoop ist einer der größten Namen in der Big -Data -Branche. Teradata ist ein relationales Datenbankverwaltungssystem und eine führende Data Warehousing -Lösung, die Datenverwaltungslösungen für Analysen bereitstellt. Es wird verwendet, um eine große Menge strukturierter Daten in einem zentralen Repository zu speichern und zu verarbeiten. Im Folgenden finden Sie einen Vergleich zwischen Kopf und Kopf zwischen den beiden Technologien.
Was ist Hadoop?
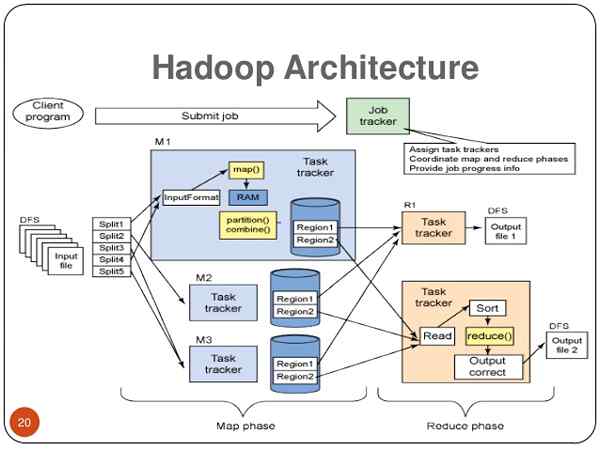
Hadoop ist das Herz von Big Data. Es handelt sich um ein Open-Source-Software-Framework, das von der Apache Software Foundation entwickelt wurde und zum Speichern und Verarbeitung verschiedener Datentypen verwendet wird, mit denen datengesteuerte Unternehmen den vollständigen Wert aus allen Daten schnell ableiten können. Hadoop ist die Antwort zur Implementierung einer Big Data -Strategie. Die ursprünglichen Schöpfer von Hadoop sind Doug Cut und Mike Cafarella. Sie arbeiteten an einem Projekt, um einen großen Webindex namens "Nutch" zu erstellen. Sie sahen die MapReduce- und GFS -Papiere von Google und fanden sie für das Projekt nützlich. Also haben sie schließlich die Konzepte aus den Arbeiten in das Projekt integriert, die schließlich die Entstehung des Hadoop -Projekts bildeten. Doug gab seinem Spielzeug -Elefanten den Namen „Hadoop“, den er später für sein Open -Source -Projekt verwendete. Hadoop speichert terabyte und sogar petabyte von Daten kostengünstig, ohne Daten zu verlieren oder Datenanalysen zu unterbrechen.

Was ist Teradata?
Teradata ist ein relationales Datenbankverwaltungssystem wie Oracle, das von einem führenden Softwareunternehmen mit demselben Namen entwickelt wurde. Teradata ist der weltweit führende Anbieter von Business Analytics Solutions, Daten- und Analyse -Lösungen sowie hybriden Cloud -Produkten und -dienste. Es bietet das relationale Datenbankverwaltungssystem in einem einzigen RDMS, das als zentrales Repository fungiert. Seine RDBMs gilt als eine führende Data Warehousing -Lösung, die die weltweit größten kommerziellen Datenbanken betreibt. Teradata bietet Entscheidungsunterstützungsfunktionen für Organisationen und Unternehmen, die Gigabyte und sogar Terabyte von Daten speichern und analysieren müssen. Das Unternehmen wurde 1979 gegründet und startete in einer Garage in Brentwood, Kalifornien. Der Name Teradata symbolisierte die Fähigkeit, Billionen von Daten Bytes zu verwalten. Das Unternehmen wurde tatsächlich von einer Gruppe von Menschen gegründet.
Unterschied zwischen Hadoop und Teradata
Technologie
- Hadoop ist eine von der Apache Software Foundation entwickelte Big -Data. Es ist eine Open-Source-Plattform, die sich mit den Big-Data-Herausforderungen befasst. Teradata hingegen ist ein vollständig skalierbares relationales Datenbanklager, das in Single RDBMS implementiert ist, das als zentrales Repository fungiert. Es ist eine führende Data Warehousing -Lösung, die die weltweit größten kommerziellen Datenbanken betreibt.
Die Architektur
- Hadoop basiert auf einer "Master-Sklaven-Architektur", in der ein Cluster aus einem einzelnen Masterknoten besteht und alle anderen Knoten Sklavenknoten sind. Die Hadoop-Architektur basiert auf drei Unterkomponenten: HDFS (Hadoop Distributed Dateisystem), MapReduce und Garn (ein weiterer Ressourcenverhandler). HDFS ist der Speicherteil der Hadoop -Architektur; MapReduce ist der Agent, der die Arbeit verteilt und die Ergebnisse sammelt. und Garn verteilt die verfügbaren Ressourcen im System.
Teradata ist eine gemeinsame Architektur, die auf einem massiv Parallel Processing (MPP) -System basiert. Die Teradata DBMS sind in allen Dimensionen einer Datenbanksystem Workload linear und vorhersehbar skalierbar. Es fungiert als einzelner Datenspeicher, der eine große Anzahl von gleichzeitigen Anfragen von mehreren Client -Anwendungen akzeptieren kann. Die Hauptkomponenten von Teradata sind Parsing Engine, BYNET und AMPs (Zugriffsmodulprozessoren).
Datentyp
- Hadoop wird verwendet, um verschiedene Datentypen zu speichern und zu verarbeiten, die es datengesteuerten Unternehmen ermöglichen. Es kann jede Art von Daten unter Verwendung mehrerer Open-Source-Tools verarbeiten-unabhängig vom Datentyp, unabhängig davon, ob es sich um strukturierte halbstrukturierte oder unstrukturierte Daten handelt. Die überlegenen Fähigkeiten von Hadoop zur Verarbeitung unstrukturierter Daten sind unübertroffen. Teradata hingegen ist eine relationale Data Warehousing -Lösung. Es ist nicht gut, um semi-strukturierte oder unstrukturierte Daten zu verarbeiten.
Hadoop vs. Teradata: Vergleichstabelle

Zusammenfassung von Hadoop vs. Teradata
Hadoop speichert terabyte und sogar petabyte von Daten kostengünstig, ohne Daten zu verlieren. Es kann jede Art von Daten mithilfe mehrerer Open-Source-Tools verarbeiten. Teradata hingegen ist eine vollständig skalierbare relationale Datenbankverwaltungslösung, die zum Speichern und Verarbeiten einer großen Anzahl strukturierter Daten in einem zentralen Repository verwendet wird. Hadoop basiert auf einer "Master-Sklaven-Architektur", bei der ein Cluster aus einem einzelnen Masterknoten und allen anderen Knoten Sklavenknoten sind, während Teradata eine gemeinsame Architektur ist.
- « Unterschied zwischen Überschuss und Mangel
- Unterschied zwischen sozialen Medien und traditionellen Medien »