

Unterschied zwischen Hadoop und Cassandra
- 3622
- 117
- Rahel Diedrich
Mit massiven Datenmengen, die durch eine massive Explosion des Internets der Dinge und die zunehmende Nutzung der sozialen Medien mit sehr hoher Geschwindigkeit generiert werden, hat die Fähigkeit, diese massiven Datenmengen zu speichern und zu analysieren, zugenommen. Hadoop ist eines der ausgefeilten Tools, die so ausgelegt sind, dass solche großen Datenmengen behandelt werden, die häufig als Big Data bezeichnet werden. Cassandra ist eine weitere hochskalierbare Datenbank, die einfach bereit ist und verwaltet wird. Aber das ist die beste Wahl - Hadoop oder Cassandra?
Was ist Hadoop?
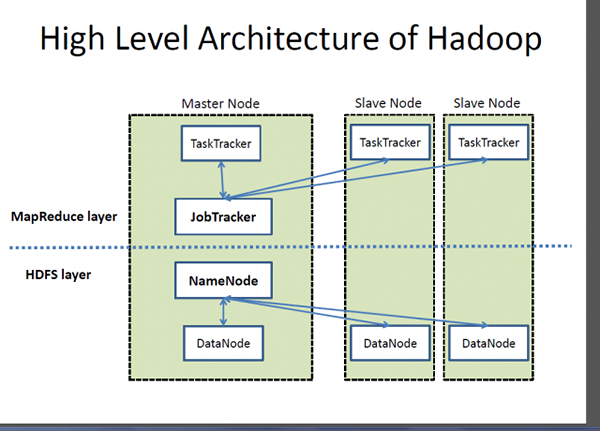
Apache Hadoop ist das De -facto -Framework für die Verarbeitung und Speicherung großer Datenmengen, die häufig als „Big Data“ bezeichnet wird. Hadoop ist der Eckpfeiler aller Big Data -Lösungen. Hadoop ist ein Projekt der Apache Software Foundation und ist ein großes verteiltes Verarbeitungssystem, mit dem große Datenmengen über die Knoten im Cluster verteilt und verarbeitet werden sollen. Es zielt nicht darauf ab, die traditionellen Datenbanksysteme zu ersetzen. In der Tat erleichtert Hadoop die Verwendung von relationalen Datenbanken, indem es die Vorgänge in Bezug auf große Datensätze beschleunigen. Hadoop basiert auf dem berühmten MapReduce -Programmiermodell, das für die Verarbeitung großer Datensätze geeignet ist, die parallel über eine Gruppe von Knoten verteilt sind. Das Hadoop Distributed Dateisystem (HDFS) ist das Datenspeicher- und Verarbeitungsdateisystem für Hadoop, das auf Rohstoffhardware ausgeführt wird und parallelen Zugriff auf große Datenmengen bietet.
Was ist Cassandra?
Apache Cassandra ist eine open-Source-, vollständig verteilte, spaltenorientierte Datenbank, die herkömmlichen Einzelmaster-Datenbanken überlegene Skalierbarkeit und Fehlertoleranz bietet. Cassandra ist eine nicht -relationale Datenbank, die auch als NOSQL -Datenbank bezeichnet wird, die ihr Verteilungsdesign auf dem Dynamo von Amazon und seinem Datenmodell auf Googles Bigtable basiert - eine Hochleistungs -NOSQL. Es handelt sich um ein verteiltes Managementsystem, mit dem große Mengen strukturierter Daten über Warenserver hinweg verarbeitet werden. Im Vergleich zu anderen beliebten verteilten Datenbanken wie HBase, Voldermort und Riak bietet Apache Cassandra eine robuste und ausdrucksstarke Schnittstelle zum Modellieren und Abfragen von Daten. Das Beste an Cassandra ist, dass es verteilt ist, was bedeutet, dass es auf mehreren Maschinen laufen kann.
Unterschied zwischen Hadoop und Cassandra
Definition
- Hadoop ist ein Apache Open-Source-Framework, das in Java geschrieben wurde und für die große Datenmengen behandelt werden sollen, die im Maßstab verarbeitet werden müssen, wenn Sie viele Daten gleichzeitig streaming oder stapelartig verarbeiten. Apache Cassandra hingegen ist eine hoch skalierbare, vollständig verteilte Datenbank, mit. Apache Cassandra bietet eine robuste und ausdrucksstarke Schnittstelle zum Modellieren und Abfragen von Daten.
Einsatz
- Hadoop ist ein skalierbares Framework, das für kostengünstige Hardware eingesetzt werden soll. Der HDFS -Speicher wird über eine Gruppe von Knoten verteilt. Eine einzelne große Datei könnte über mehrere Knoten im Cluster gespeichert werden. Es wird in einem einzelnen Rechenzentrum eingesetzt, aber sie sind alle geografisch zusammen miteinander gelegen. Cassandra hingegen wird auf sehr verteilte Weise als Ansammlung von Fällen eingesetzt, die sich alle bewusst sind, die sich voneinander bewusst sind. Daten können an eine beliebige Instanz im Cluster gelesen oder geschrieben werden, die als Knoten bezeichnet wird und die Anfrage an die Instanz weiterleitet, an der die Daten gehört.
Rahmen
- Apache Hadoop ist ein Big Data -Verarbeitungs -Framework, das auf dem berühmten MapReduce -Programmiermodell basiert. Es handelt sich um ein verteiltes Verarbeitungssystem, um große Datenmengen über die Knoten im Cluster zu verteilen und zu verarbeiten. Cassandra hingegen ist eine vollständig verteilte NoSQL -Datenbank, die eine einzigartig robuste und ausdrucksstarke Schnittstelle zum Modellieren und Abfragen von Daten bietet. Es ist nicht wie die traditionellen Datenbanksysteme; Tatsächlich speichert es Daten im Schlüsselwertpaar. Im Gegensatz zu Hadoop wird Cassandra hauptsächlich für die Echtzeit-Datenverarbeitung verwendet.
Datei Format
- Hadoop kann mit nur allen Art von Daten in einer Vielzahl von Formaten arbeiten, sei es strukturiert, halbstrukturiert oder nicht strukturiert und was auch immer Sie sich vorstellen können-Bilder, JSON, XML und so auf. Cassandra hingegen ist ein verteiltes Verwaltungssystem, das große Mengen strukturierter Daten über Waren Server hinweg verarbeitet. Darüber hinaus unterstützt Cassandra keine Bilder.
Die Architektur
- Hadoop folgt einer Meister -Sklavenarchitektur, die aus Masterknoten und Sklavenknoten besteht. Der Namemode ist der Master -Knoten und die Datanoden sind die Sklavenknoten. Normalerweise wird ein Datanode -Daemon auf jedem Sklavenmodus ausgeführt und den an jeden Datanode angeschlossenen Speicher verwaltet. Die HDFs können auf einer Vielzahl von Maschinen eingesetzt werden, die Java ausführen. Cassandra hingegen speichert Daten an verschiedenen Knoten mit einem verteilten Peer-to-Peer.
Hadoop vs. Cassandra: Vergleichstabelle

Zusammenfassung
Hadoop ist der Eckpfeiler von Big Data Solutions, die eine modernste Plattform für die Speicherung und Analyse von massiven Datensätzen und die Verbesserung der traditionellen Relational Database Management-Systeme bietet. Apache Hadoop bietet ein fehlertolerantes, verteiltes Framework für die Speicherung und Verarbeitung sehr großer Datensätze in Bezug. Cassandra ist die führende NOSQL -Datenbank, die die besten technologischen Fortschritte aus den Dynamo- und Bigtable -Papieren erzielt, um große Mengen strukturierter Daten über Rohstoffserver hinweg zu verarbeiten. Außerdem eignet sich Cassandra ideal für schnelle Online -Transaktionen, während Hadoop ideal für eine schnellere Speicherung und Abrufen von Daten ist.
- « Unterschied zwischen Omnisphere 1 und 2
- Unterschied zwischen dielektrischem Test und Isolationstest »