

Unterschied zwischen EMR und Kleber

- 2715
- 688
- Prof. Dr. Charleen Lammert
Die AWS bietet eine Vielzahl von Tools und Diensten für die Verarbeitung großer Datenmengen. Im Laufe der Jahre hat AWS viele Analysedienste aufgebaut. Abhängig von Ihrer technischen Umgebung können Sie immer das oder das andere Tool für die Datenverarbeitung basierend auf Ihren Workflows für maschinelles Lernen auswählen. Wenn es um Analyse -Workloads geht, sind Amazon EMR und AWS -Kleber die beiden beliebten Auswahlmöglichkeiten für die Verarbeitung von Daten im Maßstab. Wir werfen einen Blick auf die beiden verwalteten Dienste und versuchen, die wichtigsten Unterschiede zwischen den beiden zu verstehen. Also lasst uns anfangen.
Was ist Amazon EMR?
Amazon Elastic MapReduce (EMR) ist ein Cloud-basierter Managed-Service für die schnelle und kostengünstige Verarbeitung und Analyse von Big Data. EMR ist eine branchenführende Big-Data-Plattform, die Big-Data-Analysen mithilfe von Tools wie Apache Spark, Apache Hadoop, Apache Hive, Apache HBase, Presto usw. vereinfacht. Es begann als verwaltete Umgebung für Apache -Hadoop. EMR wurde speziell entwickelt, um die Wartungsbelastung zu verringern, indem sowohl die Computerporten als auch die On-Demand-Infrastruktur bereitgestellt werden, um so große Datenmengen zu analysieren. EMR nutzt das Amazon S3 stark, um Datensätze für die Verarbeitungs- und Analyseergebnisse zu speichern, und verwendet Amazon EC2, um Big Data auf einem Cluster virtueller Server zu verarbeiten. Es ist flexibel, anpassbar und kann sowohl für kurze als auch für lange Instanzen ausgeführt werden. EMR ist ein Hauptanwärter für die Datenverarbeitung im Maßstab.
Was ist AWS -Kleber?
AWS Glue ist ein serverfreier, vollständig verwalteter Extraktions-, Transformations- und Lade- (ETL) -Dienst von Amazon als Teil von AWS, um Daten zu kriechen, zu entdecken und zu organisieren. Es ist ein Pay-as-you-Go-Computerdienst, der automatische Schema-Inferenz für Ihre strukturierten und halbstrukturierten Datensätze bietet. Sie können die Daten und Metadaten aus mehreren Quellen wie Datenbanken extrahieren und einen Informationskatalog erstellen, der weiter verwendet werden kann, um die Daten in Ihr Zielbedarfszustand zu transformieren. Es versteht Ihre Daten, schlägt Transformationen vor und generiert ETL-Skripte. Darüber hinaus wird sie in einer Python-Shell oder vollständig verwalteten serverfreien Spark-Umgebung vollständig verwaltet ausgeführt. Basierend auf den Transformationen, die Sie auf Ihren Daten definieren, kann der Kleber automatisch Spark -Skripte generieren. Sie können sie nicht nur anpassen, sondern auch Ihre eigenen Skripts bereitstellen. Der Kleber basiert auf Spark und ist in S3, RDS, Rotverschiebung und alle JDBC -Datenspeicher integriert.
Unterschied zwischen EMR und Kleber
Werkzeug
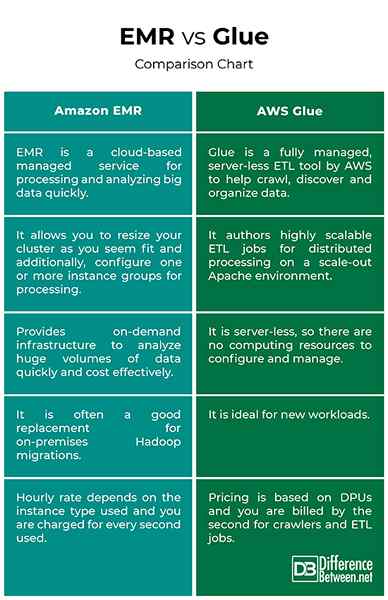
- Amazon EMR ist ein Cloud-basierter verwalteter Dienst, der das Amazon S3 stark nutzt, um Datensätze für die Verarbeitungs- und Analyseergebnisse zu speichern, und verwendet Amazon EC2, um Big Data auf einem Cluster virtueller Server zu verarbeiten. Es ist eine voll verwaltete Hadoop -Umgebung, die viele andere Projekte auf AWS unterstützt, wie Apache Spark, Apache Hive, Apache HBase, Presto usw. AWS Glue hingegen ist ein serverloses ETL-Tool, das automatische Schema-Inferenz für Ihre strukturierten und halbstrukturierten Datensätze bietet.
Preisgestaltung
- Die Preisstruktur von Amazon EMR ist einfach und vorhersehbar. Sie werden auf zweiter Basis berechnet, was bedeutet, dass Sie für jede Sekunde, die Sie verwenden. Der Stundensatz hängt vom verwendeten Instanztyp ab und beginnt ab $ 0.011 pro Stunde und steigt auf 0 $.27 pro Stunde. Die Gebühren sind wie EC2 -Preise, die den Datenverarbeitungskosten hinzugefügt wurden. Die AWS -Kleberpreise basieren auf DPUs (Datenverarbeitungseinheiten), und Sie werden von der zweiten für Crawler- und ETL -Jobs in Rechnung gestellt. Es kostet Sie normalerweise ca. $ 0.44 pro Stunde pro DPU in Schritten von 1 Sekunde, abgerundet auf die nächste Sekunde abgerundet.
Flexibilität und Skalierbarkeit
- Amazon EMR ist eine vollständig verwaltete Cluster -Plattform, die das Setup und die Verwaltung des Cluster von Apache Hadoop- und MapReduce -Komponenten vereinfacht. Es bietet eine einfache Möglichkeit, abhängig von Ihren Verarbeitungsanforderungen die Ausführung von Workloads zu skalieren. Sie können Ihren Cluster ändern, wenn Sie fit wirken, und konfigurieren Sie zusätzlich eine oder mehrere Instanzgruppen für die Verarbeitung. AWS-Kleber ist auch flexibel und leicht skalierbar, da es in einer vollständig verwalteten, serverlosen Umgebung funktioniert. IT-Autoren hoch skalierbare ETL-Jobs für die verteilte Verarbeitung in einer Skala-Out-Apache-Umgebung.
Anwendungsfall
- Amazon EMR ist eine vollständig verwaltete Umgebung, die sowohl die Computerporten als auch die On-Demand-Infrastruktur zur Analyse großer Datenmengen und Kosten effektiv analysiert. Es vereinfacht das Ausführen von Big -Data -Frameworks wie Apace Hadoop und Apache Spark auf AWS zur Verarbeitung von Big Data im Maßstab. Es ist oft ein guter Ersatz für lokale Hadoop-Migrationen. AWS Glue ist eine serverfreie ETL. Es ist ideal für neue Workloads.
EMR vs. Kleber: Vergleichstabelle
Zusammenfassung
Kurz gesagt, Amazon EMR ist eine vollständig verwaltete Umgebung, die sowohl die Computerporte als auch die On-Demand-Infrastruktur bietet, um große Datenmengen schnell und kosten effektiv zu analysieren. Wenn Sie also die gesamte Infrastruktur zur Verfügung haben, ist EMR die beste Option für Sie. AWS-Kleber hingegen ist nützlich, wenn Sie flexible Anforderungen haben und da es serverlos ist, müssen Sie keine Rechenressourcen konfigurieren und verwalten. Kleber hilft einfach dabei, Daten zu kriechen, zu entdecken und zu organisieren, die Sie besitzen.
- « Unterschied zwischen Lungeninfiltrat und Konsolidierung
- Unterschied zwischen Antikörpertest und PCR -Test »