

Unterschied zwischen Clustering und Klassifizierung
- 1037
- 164
- Hugo Poehn
Clustering- und Klassifizierungstechniken werden bei maschinellem Lern-, Informationsabruf-, Bilduntersuchungs- und verwandten Aufgaben verwendet.
Diese beiden Strategien sind die beiden Hauptabteilungen von Data Mining -Prozessen. In der Datenanalyse -Welt sind diese für die Verwaltung von Algorithmen von wesentlicher Bedeutung. Insbesondere teilen diese beiden Prozesse Daten in Sätze. Diese Aufgabe ist im heutigen Informationsalter von großer Bedeutung, da die immense Zunahme der Daten in Verbindung mit der Entwicklung treffend erleichtert werden muss.
Insbesondere Clustering und Klassifizierung tragen dazu bei.
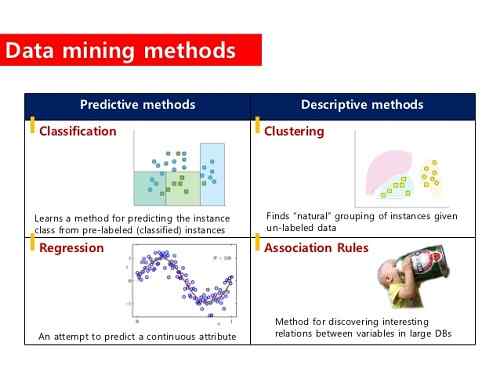
Was ist Clustering?
Grundsätzlich beinhaltet das Clustering die Gruppierung von Daten in Bezug auf ihre Ähnlichkeiten. Es befasst sich in erster Linie mit Entfernungsmaßnahmen und Clustering -Algorithmen, die die Differenz zwischen den Daten berechnen und diese systematisch dividieren.
Zum Beispiel werden Schüler mit ähnlichen Lernstilen zusammengefasst und getrennt von denen mit unterschiedlichen Lernansätzen unterrichtet. Im Data Mining wird die Clusterbildung am häufigsten als „unbeaufsichtigte Lerntechnik“ bezeichnet, da die Gruppierung auf einem natürlichen oder inhärenten Merkmal basiert.
Es wird in mehreren wissenschaftlichen Bereichen wie Informationstechnologie, Biologie, Kriminologie und Medizin angewendet.
Eigenschaften des Clustering:
- Keine genaue Definition
Das Clustering hat keine genaue Definition, deshalb gibt es verschiedene Clustering -Algorithmen oder Clustermodelle. Grob gesagt sind die beiden Arten von Clustering hart und weich. Hartes Clustering befasst sich mit der Kennzeichnung eines Objekts als einfach zu einem Cluster oder nicht. Im Gegensatz dazu gibt ein weiches Clustering oder Fuzzy -Clustering den Grad an, wie etwas zu einer bestimmten Gruppe gehört.
- Schwer bewertet zu werden
Die Validierung oder Bewertung von Ergebnissen aus der Clustering -Analyse ist aufgrund ihrer inhärenten Untätigkeit häufig schwer zu ermitteln.
- Unbeaufsichtigt
Da es sich um eine unbeaufsichtigte Lernstrategie handelt, basiert die Analyse lediglich auf aktuellen Merkmalen. Somit ist keine strenge Regulierung erforderlich.
Was ist Klassifizierung?
Die Klassifizierung beinhaltet die Zuweisung von Etiketten an vorhandene Situationen oder Klassen. Daher der Begriff „Klassifizierung“. Zum Beispiel werden Schüler, die bestimmte Lernmerkmale ausstellen, als visuelle Lernende klassifiziert.
Die Klassifizierung wird auch als „überwachte Lerntechnik“ bezeichnet, wobei Maschinen aus bereits beschrifteten oder klassifizierten Daten lernen. Es ist sehr anwendbar für Mustererkennung, Statistik und Biometrie.
Merkmale der Klassifizierung
- Verwendet einen „Klassifikator“
Um Daten zu analysieren, ist ein Klassifizierer ein definierter Algorithmus, der eine Information konkret einer bestimmten Klasse konkret ordnet. Zum Beispiel würde ein Klassifizierungsalgorithmus ein Modell trainieren, um festzustellen, ob eine bestimmte Zelle bösartig oder gutartig ist.
- Bewertet durch gemeinsame Metriken
Die Qualität einer Klassifizierungsanalyse wird häufig durch Präzision und Rückruf bewertet, die beliebte metrische Verfahren sind. Ein Klassifikator wird hinsichtlich seiner Genauigkeit und Empfindlichkeit bei der Identifizierung der Ausgabe bewertet.
- Beaufsichtigt
Die Klassifizierung ist eine überwachte Lerntechnik, da sie zuvor bestimmte Identitäten basierend auf vergleichbaren Merkmalen zuweist. Es zieht eine Funktion aus einem beschrifteten Trainingssatz ab.
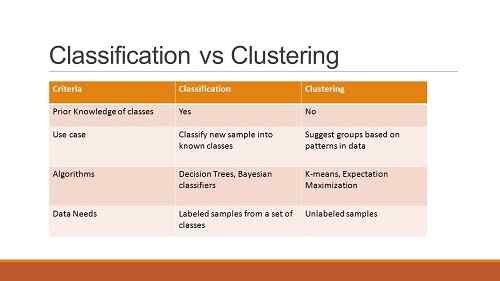
Unterschiede zwischen Clustering und Klassifizierung
- Aufsicht
Der Hauptunterschied besteht.
- Verwendung des Trainingssatzes
Das Clustering verwendet keine drängenden Schulungssätze, bei denen es sich um Gruppen von Instanzen handelt, die zur Generierung der Gruppierungen eingesetzt werden, während die Klassifizierung Schulungssätze für die Identifizierung ähnlicher Merkmale unterbrochen benötigt.
- Beschriftung
Das Clustering funktioniert mit nicht markierten Daten, da es keine Schulung erfordert. Auf der anderen Seite befasst sich die Klassifizierung sowohl mit nicht markierten als auch mit beschrifteten Daten in ihren Prozessen.
- Ziel
Clustering -Gruppen Objekte mit dem Ziel, die Beziehungen einzugrenzen und neuartige Informationen aus verborgenen Mustern zu erlernen, während die Klassifizierung feststellt.
- Einzelheiten
Während die Klassifizierung nicht angibt, was gelernt werden muss.
- Phasen
Im Allgemeinen besteht das Clustering nur aus einer einzelnen Phase (Gruppierung), während die Klassifizierung zwei Phasen aufweist: Training (Modell lernt aus Trainingsdatensatz) und Tests (die Zielklasse wird vorhergesagt).
- Randbedingungen
Die Bestimmung der Randbedingungen ist im Klassifizierungsprozess im Vergleich zum Clustering von großer Bedeutung. Zum Beispiel ist bei der Festlegung der Klassifizierung zu wissen, den prozentualen Bereich von „niedrig“ im Vergleich zu „moderat“ und „hoch“ zu kennen.
- Vorhersage
Im Vergleich zu Clustering ist die Klassifizierung stärker mit der Vorhersage verbunden, da sie insbesondere darauf abzielt, Zielklassen zu identifizieren. Zum Beispiel kann dies bei der Erkennung von Gesichtszählpunkten angewendet werden, da es verwendet werden kann, ob ein bestimmter Zeuge lügt oder nicht.
- Komplexität
Da die Klassifizierung aus mehr Stadien besteht, sich mit Vorhersage befasst und Abschlüsse oder Ebenen beinhaltet.
- Anzahl der wahrscheinlichen Algorithmen
Clustering -Algorithmen sind hauptsächlich linear und nichtlinear, während die Klassifizierung aus mehr algorithmischen Werkzeugen wie linearen Klassifikatoren, neuronalen Netzwerken, Kernelschätzungen, Entscheidungsbäumen und Support -Vektor -Maschinen besteht.
Clustering vs -Klassifizierung: Tabelle zum Vergleich des Unterschieds zwischen Clustering und Klassifizierung
| Clustering | Einstufung |
| Unbeaufsichtigte Daten | Übersichtliche Daten |
| Läuft keine hochwertigen Trainingssätze | Hat hochwertige Trainingssätze |
| Arbeitet ausschließlich mit nicht beliebigen Daten | Beinhaltet sowohl nicht markierte als auch markierte Daten |
| Ziel ist es, Ähnlichkeiten zwischen Daten zu identifizieren | Ziel ist zu überprüfen, wo ein Datum gehört |
| Gibt die erforderliche Änderung an | Gibt keine erforderliche Verbesserung an |
| Hat eine einzelne Phase | Hat zwei Phasen |
| Die Bestimmung der Randbedingungen ist nicht von größter Bedeutung | Die Identifizierung der Randbedingungen ist für die Ausführung der Phasen von entscheidender Bedeutung |
| Befasst sich im Allgemeinen nicht mit Vorhersage | Befasst sich mit Vorhersage |
| Beschäftigt hauptsächlich zwei Algorithmen | Hat eine Reihe wahrscheinlicher Algorithmen zu verwenden |
| Prozess ist weniger komplex | Prozess ist komplexer |
Zusammenfassung zu Clustering und Klassifizierung
- Sowohl Clustering- als auch Klassifizierungsanalysen sind in Datenminenprozessen stark eingesetzt.
- Diese Techniken werden in einer Vielzahl von Wissenschaften angewendet, die für die Lösung globaler Probleme von wesentlicher Bedeutung sind.
- Meistens befasst sich das Clustering mit unbeaufsichtigten Daten; Somit ist die nicht beliebige während der Klassifizierung mit beaufsichtigten Daten funktioniert; So markiert. Dies ist einer der Hauptgründe, warum Clustering während der Klassifizierung keine Schulungssätze benötigt.
- Im Vergleich zum Clustering sind mehr Algorithmen zugeordnet.
- Clustering versucht zu überprüfen. Dies macht den Clustering -Prozess stärker auf Randbedingungen und die Klassifizierungsanalyse in dem Sinne, dass es mehr Stufen beinhaltet.