

Unterschied zwischen Absack- und Zufallswald
- 3776
- 101
- Prof. Dr. Charleen Lammert
Im Laufe der Jahre waren mehrere Klassifikatorsysteme, auch Ensemble -Systeme genannt. Es zog das Interesse von Wissenschaftlern aus mehreren Bereichen, darunter maschinelles Lernen, Statistiken, Mustererkennung und Wissensentdeckung in Datenbanken. Im Laufe der Zeit haben sich die Ensemble-Methoden in einem breiten Spektrum von Problembereichen und realen Anwendungen als sehr effektiv und vielseitig erwiesen. Ursprünglich entwickelt, um die Varianz im automatisierten Entscheidungssystem zu verringern, wurden Ensemble-Methoden seitdem verwendet, um eine Vielzahl von Problemen des maschinellen Lernens anzugehen. Wir geben einen Überblick über die beiden bekanntesten Ensemble -Algorithmen - Sacking und zufälligen Wald - und diskutieren dann die Unterschiede zwischen den beiden.
In vielen Fällen wurde nachgewiesen. Das Backen ist eines der ältesten und einfachsten Ensemble-basierten Algorithmen, die auf baumbasierte Algorithmen angewendet werden können, um die Genauigkeit der Vorhersagen zu verbessern. Es gibt noch eine weitere verbesserte Version des Sacking, die als Zufallswaldalgorithmus bezeichnet wird und im Wesentlichen ein Ensemble von Entscheidungsbäumen ist, die mit einem Sackmechanismus trainiert werden. Mal sehen, wie der zufällige Waldalgorithmus funktioniert und wie es sich unterscheidet, als in Ensemble -Modellen einzupacken.
Eintacken
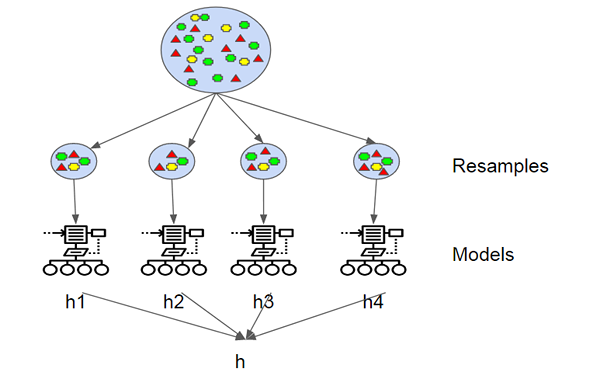
Die Bootstrap-Aggregation, auch als Bagging bekannt, ist eine der frühesten und einfachsten Algorithmen auf Ensemble-basierten, um Entscheidungsbäume robuster zu machen und eine bessere Leistung zu erzielen. Das Konzept hinter dem Tagging besteht darin, die Vorhersagen mehrerer Grundlerner zu kombinieren, um eine genauere Ausgabe zu erstellen. Leo Breiman stellte 1994 den Algorithmus zum Bagging vor. Er zeigte, dass die Bootstrap -Aggregation die gewünschten Ergebnisse zu instabilen Lernalgorithmen bringen kann, bei denen kleine Änderungen an den Trainingsdaten große Unterschiede in den Vorhersagen verursachen können. Eine Bootstrap ist eine Probe eines Datensatzes mit Ersatz und jede Probe wird erzeugt, indem der Trainingssatz der M-Größe gleichmäßig abtastet, bis ein neuer Satz mit M-Instanzen erhalten wird.
Zufallswald
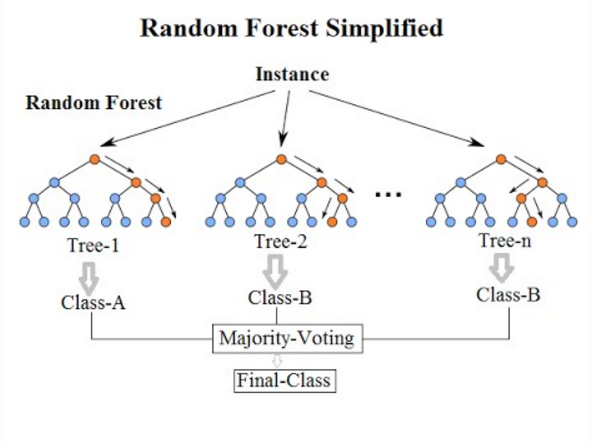
Random Forest ist ein überwachter Algorithmus für maschinelles Lernen, der auf Ensemble -Lernen und einer Entwicklung von Breims ursprünglichem Bagging -Algorithmus basiert. Es ist eine große Verbesserung gegenüber abgepackten Entscheidungsbäumen, um mehrere Entscheidungsbäume aufzubauen und sie zu aggregieren, um ein genaues Ergebnis zu erzielen. Breiman fügte eine zusätzliche zufällige Variation in das Sagging -Verfahren hinzu, was zwischen den resultierenden Modellen zu einer größeren Vielfalt führte. Zufällige Wälder unterscheiden. Alle Entscheidungsbäume, aus denen sich ein zufälliger Wald zusammensetzt. Da es die Überanpassung minimiert, ist es tendenziell genauer als ein einzelner Entscheidungsbaum.
Unterschied zwischen Absack- und Zufallswald
Grundlagen
- Sowohl das Backen als auch zufällige Wälder sind Ensemble-basierte Algorithmen, die darauf abzielen, die Komplexität von Modellen zu verringern, die die Trainingsdaten überwinden. Die Bootstrap -Aggregation, auch Bagging genannt, ist eine der ältesten und leistungsstarken Ensemble -Methoden, um eine Überanpassung zu verhindern. Es ist eine Meta-Technik, die mehrere Klassifikatoren verwendet, um die Vorhersagegenauigkeit zu verbessern. Das Einbacken bedeutet einfach, zufällige Stichproben aus der Trainingsprobe zum Ersatz zu ziehen, um ein Ensemble verschiedener Modelle zu erhalten. Random Forest ist ein überwachter Algorithmus für maschinelles Lernen, der auf Ensemble -Lernen und einer Entwicklung von Breims ursprünglichem Bagging -Algorithmus basiert.
Konzept
- Das Konzept der Bootstrap -Probenahme (Bagging) besteht darin, eine Reihe von unbefristeten Entscheidungsbäumen auf verschiedenen zufälligen Teilmengen der Trainingsdaten zu schulen und mit Ersatz zu proben, um die Abweichung der Entscheidungsbäume zu verringern. Die Idee ist, die Vorhersagen mehrerer Grundlerner zu kombinieren, um eine genauere Ausgabe zu erstellen. Bei zufälligen Wäldern wird eine zusätzliche zufällige Variation in das Bagging -Verfahren hinzugefügt, um eine größere Vielfalt zwischen den resultierenden Modellen zu schaffen. Die Idee hinter zufälligen Wäldern ist es, mehrere Entscheidungsbäume zu bauen und sie zu aggregieren, um ein genaues Ergebnis zu erzielen.
Ziel
- Sowohl eingepackte Bäume als auch zufällige Wälder sind die häufigsten Ensemble -Lerninstrumente, mit denen sich eine Vielzahl von Problemen mit maschinellem Lernen befassen. Bootstrap-Probenahme ist ein Meta-Algorithmus, der die Genauigkeit und Stabilität von maschinellem Lernmodellen unter Verwendung des Ensemble-Lernens verbessern und die Komplexität von Überanpassungsmodellen verringert. Der zufällige Waldalgorithmus ist sehr robust gegen Überanpassung und ist gut mit unausgeglichenen und fehlenden Daten gut. Es ist auch die bevorzugte Wahl des Algorithmus für den Aufbau von Vorhersagemodellen. Ziel ist es, die Varianz zu verringern, indem mehrere tiefe Entscheidungsbäume gemessen werden, die auf verschiedenen Datenproben geschult wurden.
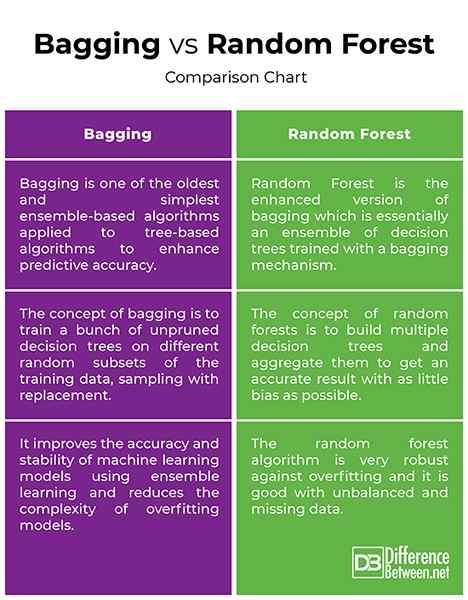
Bagging vs. Zufälliger Wald: Vergleichstabelle
Zusammenfassung
Sowohl eingepackte Bäume als auch zufällige Wälder sind die häufigsten Ensemble -Lerninstrumente, mit denen sich eine Vielzahl von Problemen mit maschinellem Lernen befassen. Das Backen ist eines der ältesten und einfachsten Ensemble-basierten Algorithmen, die auf baumbasierte Algorithmen angewendet werden können, um die Genauigkeit der Vorhersagen zu verbessern. Zufällige Wälder hingegen ist ein überwachtes Algorithmus für maschinelles Lernen und eine verbesserte Version des Bootstrap -Stichprobenmodells, die sowohl für Regressions- als auch für Klassifizierungsprobleme verwendet werden. Die Idee hinter dem zufälligen Wald besteht darin, mehrere Entscheidungsbäume zu bauen und sie zu aggregieren, um ein genaues Ergebnis zu erzielen. Ein zufälliger Wald ist tendenziell genauer als ein einzelner Entscheidungsbaum, da er die Überanpassung minimiert.
- « Unterschied zwischen digitalem Wachhund und Hikvision
- Unterschied zwischen Bronchitis und Bronchiektase »